あなたの「数字を読む力」は? 何問正解できる? クイズで学ぶ“データサイエンティストの仮説思考”
データのプロである「データサイエンティスト」の孝忠(こうちゅう)大輔氏が登壇し、クイズや例題を通じてデータの正しい読み解き方や、仮説思考のポイントを解説。
2025年7月22日 7:00
Webキャンペーン立案や市場分析など、データを読み解き検証と改善のサイクルを回し続けていく必要がある。
ただ、本当にデータを活用できているだろうか? 勘や経験に頼り、前例踏襲のサイクルに陥ってはいないだろうか? 「Web担当者Forum ミーティング 2025 春」にデータのプロである「データサイエンティスト」の孝忠(こうちゅう)大輔氏が登壇し、クイズや例題を通じてデータの正しい読み解き方や、仮説思考のポイントを解説した。

データ活用できている?
たとえば、キャンペーン施策を実施して、報告書にまとめようとすると、どの切り口でデータをまとめるべきかわからず、困った経験はないだろうか。
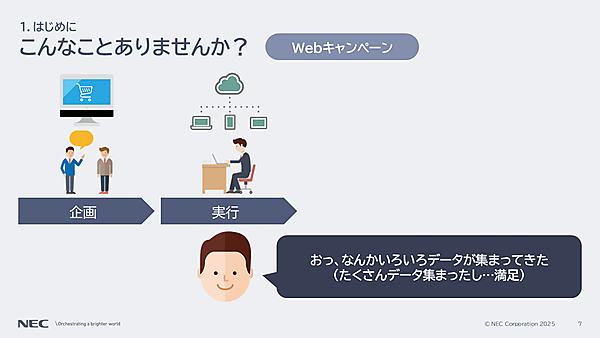
結果、次に向けて改善しようと思っても、知見や改善に向けたヒントを得られないまま、同じキャンペーンをやり続けてしまう。
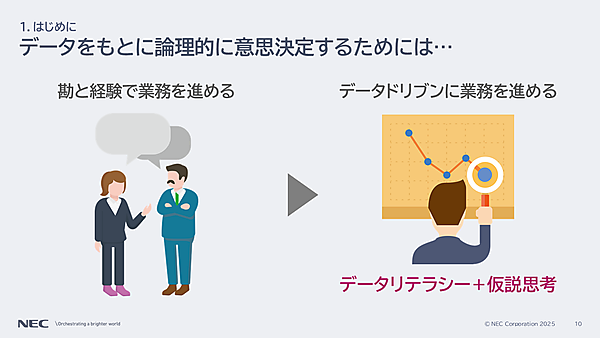
このようなサイクルを繰り返さないために、どうすればいいか。そのためには、勘と経験で業務を進めるのではなく、データドリブンに業務を進める必要があります。それには「データリテラシー」と「仮説思考」が大切です(孝忠氏)
「読み・書き・そろばん」→「数理・データサイエンス・AI」へ
データリテラシーとは、データ全般に関する知識や、それを活用する能力を指す。孝忠氏によれば、データリテラシーという言葉が注目されるようになったのは、政府が発表した「AI戦略2019」がきっかけだという。
江戸時代においては「読み・書き・そろばん」が重視されたが、現代のデジタル社会ではそれが「数理・データサイエンス・AI」になると内閣府から提言された。

2020年度に小学校でプログラミング教育が、2022年度から高校の授業で「情報Ⅰ」が必須化された。また大学・高専においても2020年度から、文系・理系を問わず全学部で数理・データサイエンス・AI関連の教育が行われるようになった。
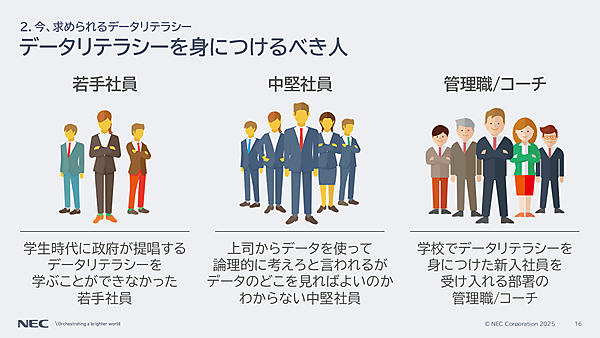
若手・中堅・管理職で広がるデータリテラシー格差
つまり、今の学生はデータリテラシーを学校教育の中で学んでいる。日本の未来にとっては良いことだが、「データリテラシー格差が広がる危険性がある」と孝忠氏は指摘する。
たとえば、今年入社した新入社員はデータリテラシーに関する知識をある程度備えている。対して、既存社員の学生時代は、文系/理系に分かれており、確率や統計を少しかじった程度の知識しか備わっていない。リテラシー格差を生まないため、社会人もデータリテラシーを身につける必要がある。
クイズで学ぶ「データリテラシー」
では、データリテラシーとは具体的にどういったもので、どんなスキルを身につければよいのか。データを読み解くポイントを、クイズを通じて解説していった。
1つ目のクイズは「データを読む」ためのクイズだ。
クイズ1
厚生労働省の国民基礎調査によると、2023年の国民の平均所得金額は524万円であった。次の選択肢の中から正しいものを選べ
- 多くの世帯では500万円~600万円の所得がある
- 半分以上の世帯では、524万円以上の所得がある
- データの分布を見ないと、どの所得の世帯が多いかわからない
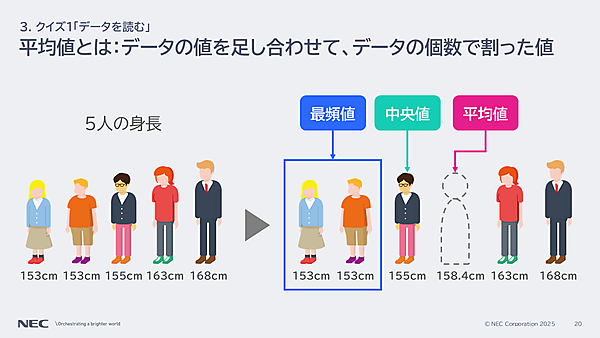
この問題の前段として備えておきたい知識が、最頻値・中央値・平均値の違いである。下図の「5人の身長のデータ」で言葉の違いを簡単に説明しておく。
- 最頻値: 最も頻度の多い値。このケースでは最頻値は153cm
- 中央値: データの真ん中の値。このケースでは中央値は155cm
- 平均値: すべての身長を足し合わせて5で割った数。このケースでは158.4cm
では、クイズの解説に戻ろう。クイズの出典である厚生労働省 国民基礎調査 2023年度調査の年収分布図を見ると、平均所得金額は524万円だが、中央値は405万円、最頻値は100~200万円だった。つまり、答えは次の通り。
クイズ1の答え3.データの分布を見ないと、どの所得の世帯が多いかわからない
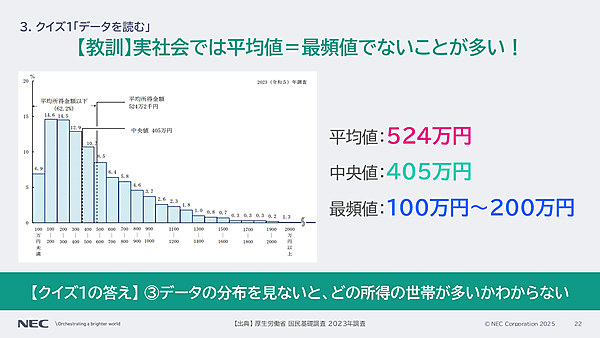
ここからわかるのは、平均値の扱いの難しさだ。アンケートや市場動向調査で平均値はよく用いられるが、分布を見て判断しないと危険である。
実社会では、平均値は最頻値ではないことが多いです。平均値を見たときに、その値は最頻値であったり中央値であったり、真ん中の値なのかというのは常に意識しないと、判断を誤る可能性があります。これは現在は大学で教えられている内容なので、みなさんもデータを適切に読めるようになりましょう(孝忠氏)
クイズ2
メッセージとグラフの内容が一致していない不適切なグラフを選べ
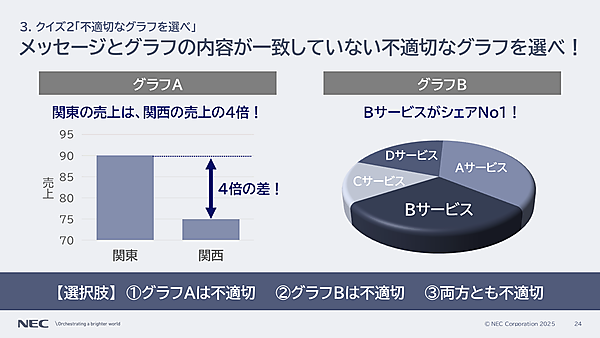
- グラフAは不適切
- グラフBは不適切
- 両方とも不適切
続いては、不適切なグラフを選ぶ問題だ。グラフAは「関東の売上は、関西の売上の4倍」とあるが、グラフの軸が0から始まっていない。売上を数字で見ると関東は90、関西は75で、差は15しかない。項目間の差を誇張したグラフとなっている。グラフはメモリを含めて読まないと危険だ。
グラフBは「Bサービスがシェアナンバー1」を訴求し、3D表示グラフで表現している。孝忠氏によると、3Dグラフだと差が分かりづらく、かつ数値の表記がない。これを円グラフにして、数字を加えたのが以下のグラフだ。つまり答えは、次の通り。
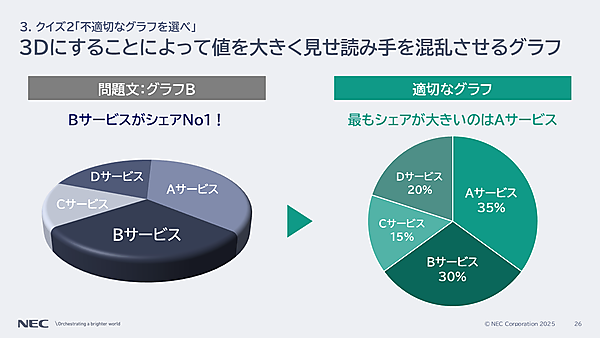
クイズ2の答え3.両方とも不適切
読み手に誤解を与えてしまうグラフは作成してはいけない。
クイズで学ぶ「仮説思考」 4ステップの思考プロセス
続いて、「仮説思考」についてもクイズを例に、その思考プロセスを解説していった。
クイズ
ある国のマーケット規模を調べるために、各家庭の世帯収入を調査しましたが、1名だけ世帯収入を回答してくれませんでした。Zさんの世帯収入を予測せよ
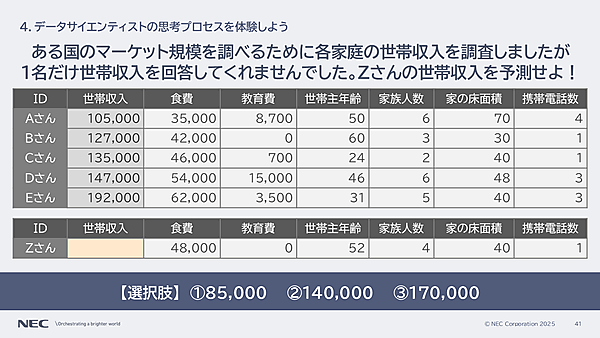
- 85,000
- 140,000
- 170,000
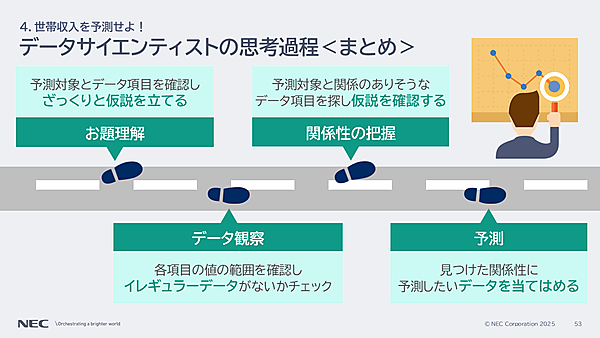
思考プロセス① お題の理解
データサイエンティストが問題を渡されたとき、はじめに何をするのかというと、“お題を理解すること”だという。
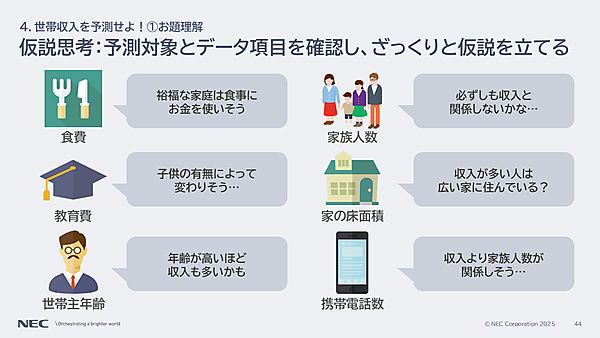
問題文を読むと、予測対象は世帯収入。ヒントとして、食費や教育費など6つのデータが示されている。最初にやることは、今回のお題は「6つのデータ項目を活用して、世帯収入を予測すること」だと把握します(孝忠氏)
次に「仮説を立てる」。データを先に見てしまうと、何を調べているかわからなくなってしまうので、データを見る前に仮説を立てるという。
たとえば、「裕福な家庭は食事にお金を使っていそう」「子どもの有無によって教育費が変わりそう」「世帯主の年齢が高い層ほど収入が多いかも」など。これが仮説だ。
その仮説をベースに、データの観察をしていく。
思考プロセス② データ観察
データの観察では、各項目の範囲を確認し、イレギュラーデータがないかをチェックする。たとえば、データの上限・下限を確認してみる。
- 世帯収入の幅: 105,000 ~ 192,000
- 食費: 35,000 ~ 62,000
- 家族人数: 2 ~ 6 など
ここでもし、世帯主年齢に「300歳」というデータがあれば、それは間違ったデータである可能性が高い。その場合、そのデータで分析を続けても使えないので、イレギュラーなデータの除去が必要になってくる。一方、教育費が「0」という世帯があっても、子どものいない世帯や成人しているケースもあるので問題ない。このようにデータを観察・チェックする。
思考プロセス③ 関係性の把握
立てた仮説をもとに、各データの関係性を把握していくのが次のステップだ。
「裕福な家庭は食事にお金を使っていそう」という仮説を検証するには、世帯収入×食費を見ればよい。データを見ると、関係性がありそうだとわかる。逆に、世帯収入と教育費、世帯収入と世帯年齢には関係がなさそうだとわかる。
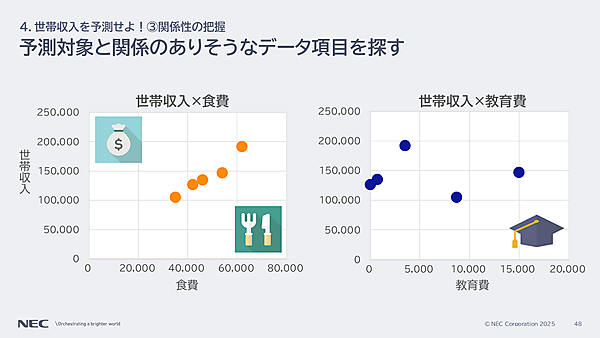
立てた仮説が外れても構いません。逆に仮説でこうなるかなと思っていたからこそ、違うと気付ける。その気付きはとても重要です(孝忠氏)
思考プロセス④ 予測
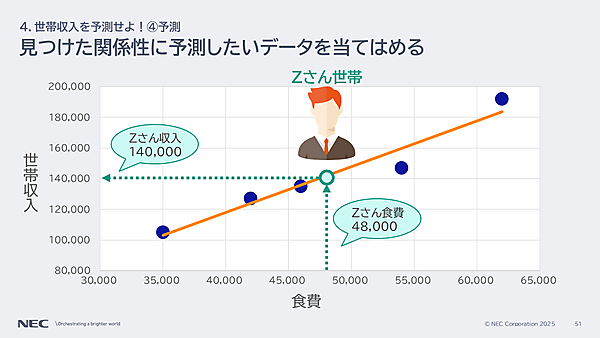
今回のクイズは、ある世帯の世帯収入を予測するのが目的だ。
仮説を複数立てたが、データを見ると、最も関係性があるのは世帯収入と食費だった。Zさん世帯の食費は「48,000」なので、これをデータに当てはめると答えは、次の通りになるだろう。
クイズの答え2. 140,000
データサイエンティストはこのような思考プロセスを踏んでいるのである。
データサイエンティストの思考過程をまとめたのが以下の図だ。
「データリテラシー」と「仮説思考」を身につけ、データドリブンに業務を進めよう!
「データリテラシー」と「仮説思考」が身につくと、孝忠氏が講演冒頭で説明したWebキャンペーンの進め方が変わってくる。企画段階では今回のキャンペーンで何を検証するのか、仮説を立てるところがスタート地点になる。
企画時に仮説を立てておけば、仮説を検証するためにどんなデータが必要かわかる。キャンペーンを行い、検証フェーズでは集めたデータを分析するのではなく、立てた仮説が正しかったかを検証するのでポイントを絞った検証が行える。その後の改善活動も、仮説検証の結果を踏まえて、次回のキャンペーンはこうしようと明確に言えるようになる。このサイクルを回していくことが重要だ。
何度も言いますが、仮説は間違っていても構いません。仮説と違っている時ほど、むしろ新しい知見を見つけられるチャンスです(孝忠氏)
「AI戦略2019」の発表から6年が経過した。学校でデータリテラシー教育を受けた学生たちが、社会人となりつつある。そうした世代だけが頑張るのではなく、「我々の世代もデータリテラシーと仮説思考を身につけて、データドリブンに業務を進めていくことが重要だ」と、孝忠氏は講演を締めくくった。
なお本講演は、一般社団法人データサイエンティスト協会とのコラボ企画として開催され、日本電気株式会社の孝忠氏が協力した形だ。同協会は2013年5月に設立され、新しい職業であるデータサイエンティストについて、職業としての確立と地位向上を目指して活動している。

\ 【参加無料】2026年8月27日(木)開催 /

- この記事のキーワード
関連記事
【DL期間終了】明日から活かせる! AI時代のマーケティング戦略 〜実務者が知るべき成功のヒント〜
2025年11月7日 7:00
マーケティングは科学的アプローチに近づく、数字は仕事をスムーズに進める共通言語
2014年6月6日 9:00
スマホ通信サービスの乗り換えを検討する理由、「料金」「他社の特典」など【週間ランキング】
2025年7月30日 8:00
「統計思考」を武器にする! ビジネスパーソンが身につけておきたい基礎分析と実務活用イメージ
2023年10月18日 7:00
「数字が苦手」だったメルカリのデータアナリストが教える、データ分析の第一歩
2024年2月8日 7:00
マネージャー必見! PDCAサイクルは顧客視点を加えることで加速し、顧客の理解も深まる
2021年2月1日 7:00
バックナンバー
この記事の筆者
筆者の人気記事
【計算できる?】5800円の2割引はいくら安くなる? 「割合」に強くなるマーケター算数基礎講座
2024年5月8日 7:00
パーセプションフローモデルとは マーケティング的意味や事例・作り方
2018年11月22日 7:00
LINEの利用者・普及率は? 他SNSユーザー数や人口と比べた
2020年6月17日 7:00
話題の「ChatGPT」こんなに使えたら本当にすごい! 目からウロコの使い方を解説|GPTs活用事例も
2024年1月24日 7:00
Webサイトリニューアルの7ステップと、よりよいサイトを作るための「要件定義」の勘所
2018年7月12日 7:00
「数字が苦手」だったメルカリのデータアナリストが教える、データ分析の第一歩
2024年2月8日 7:00




