2026年のSEOで「キーワード」は重要なのか? SERP分析1000件で見えてきたGoogleの「理解力」
「検索キーワードが1つも被らないのに上位表示される」のはなぜ? 1000件のロングテールクエリから見えた最新SEOのキーワード戦略
5月25日 7:05
キーワードは重要だ。グーグルで検索キーワードを入力したり、Geminiでプロンプトを入力したりするときは、その質問に対する回答が得られるものと期待する。
極端な例を考えてみよう。「best suvs of 2026」(2026年最高のSUV※)という検索キーワードを入力した場合、次のような結果が表示されると思うだろうか?
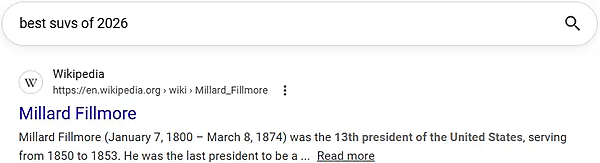
もちろん思わない。ウィキペディアがいかにオーソリティの高いサイトであろうと、そのSEO管理がいかに優れていようと、「第13代米国大統領のミラード・フィルモア」が「2026年のSUV」と何の関係もないのは明らかだ。
「top high-end sport utility vehicles」(最高級のスポーツ用多目的車)と検索して、次の結果が表示されたらどうだろうか?
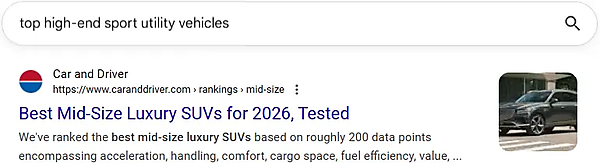
君は驚くだろうか? 答える前に、次の点を考えてみてほしい。このページのタイトルには「top」も「high-end」も「sport utility vehicles」も含まれていないのに、それでも検索結果に表示される。しかし僕たち人間は、これら2つのフレーズが極めて似通った概念を表していることを直感的に理解できる。
「機械学習(ML)」や「自然言語処理(NLP)」の進歩により、グーグルが年を追うごとに「意味的な類似性」や「単語の意味」をより正確に理解できるようになっていることを、僕たちSEO担当者はよく知っている。
こうしたことから、はるかに複雑な疑問が浮かび上がる……。
今のSEOにおいて、キーワードはどれぐらい重要なのか?
キーワードはどれほど重要か
グーグルは数年前から、同義語を理解する能力をある程度備えていた。「cell phone」(携帯電話)を検索した2012年の次の例を考えてみよう(出典はInternet Archive)。
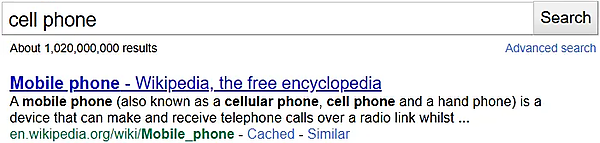
グーグルは、「cell phone」の検索に「mobile phone」や「cellular phone」が合致することを明確に認識していた。これは、グーグルが「ハミングバードアップデート」や「テキストエンベディング」をリリースする約1年前であり、大規模言語モデル(LLM)が一般公開されるより10年も前のことだ。
グーグルの機能とともに検索ユーザー自身も進化しており、自然な言葉を使う傾向が強まっている。2026年には、「スマートフォン」で検索するよりも、「カメラの性能が良い手頃な価格のAndroidスマホは?」などと検索する人の方が多いだろう。このように複雑な質問でもグーグルは正しく解釈できると、ユーザーは考えている。
では、グーグルはどれほど改善したのだろうか? また、その改善は測定できるか?
ロングテールの検索クエリ1000件に対して、検索結果8703件
僕たちは、プロンプト追跡に特化して構築され、20の業界カテゴリを網羅する「ロングテール」のクエリ1000件からなる研究コーパスを使うことにした。次にサンプルクエリをいくつか示す。
「eコマースで成功するために追跡すべき指標は?」
「ワークアウトは朝にする方が良いか?」
「ストリーミングサービスは、私がオフラインで視聴したコンテンツを追跡しているか?」
こうした1000件のクエリを米国のデスクトップ版グーグルで検索し、特に1ページ目のオーガニック結果に注目した。ここでは、8703件のオーガニック結果と表示タイトルが得られた(SERPの機能により、1ページ目に表示されるオーガニック結果が10件に満たない場合もある)。
3つの方法で類似性を測定してみた
グーグルの現在の機能をより深く理解するために、僕たちは3つの指標を用いてクエリとオーガニック結果のタイトルを比較した(グーグルに表示されるタイトルであり、title要素ではない)。3つの指標とは、次のとおりだ:
完全一致 ―― 完全一致は文字とおりの意味だが、少し柔軟性を持たせた。「大文字と小文字や句読点を正規化し、複数形を除外」したうえで、クエリ全体が含まれるタイトルであればすべて許容することにした。
ジャッカード類似度を用いた部分一致 ―― 部分一致を分析するために、ジャッカード類似度を用いた。これは、2つの集合間で共通する要素(この場合は単語)の数と、両方の集合に固有の要素の数を比較して測定するものだ。簡単に言えば、「固有の単語の総数」に占める「2つの文字列の間で共通する単語の数」の割合であり、0.0~1.0の尺度で測定する。
ベクトルデータのコサイン類似度を用いた意味的一致 ―― 最後に、文字列をベクトル埋め込み変換した状態でコサイン類似度を算出した。これは意味的な関係、要するに「意味」を捉えるものだ。具体的には、768次元のNomic埋め込みを使用した。コサイン類似度も0.0~1.0の尺度で類似度を測定する。
それぞれの分析手法での統計データといくつかの例を見てみよう。
※Web担編注 以下、説明のニュアンスを損なわないように英語版の検索結果のままだが、「検索ボックスに入力されているクエリ」と「検索結果に表示されているタイトル」が、「文字列としてどれぐらい一致しているか」「文字列は違っても意味的に同じか」という観点で見てほしい。
完全一致のデータと例
→クエリの文字列がそのまま含まれているか
より柔軟性を持たせた完全一致の場合でも、クエリ全体が含まれる表示タイトルはわずか43件(0.49%)だった。
たとえば次に示す例は、「検索クエリ」と「検索結果でのタイトル表示」がハイフン(-)だけが異なる状態で完全一致しているものだ:
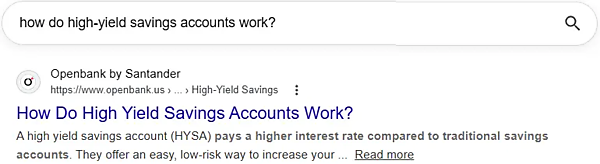
完全一致だがタイトルには検索クエリに加えて他の文字が少し含まれている、そんな例もあった(次の例では「The」と「Services」):
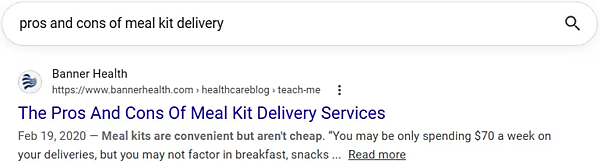
完全一致が0.49%ということは、逆に言えば表示タイトルの99.51%にはクエリ全体が含まれていなかったということだ。ロングテールクエリのデータセットであることを考えれば驚く人はほとんどいないと思うが、キーワードスタッフィングの時代からSEOがいかに進化したかを如実に示している。
ジャッカード類似度のデータと例
→クエリの文字列の一部が使われているか
ここからがさらに興味深い。表示されたタイトル8703件の平均ジャッカード類似度は0.23だった(ジャッカード類似度はかなり厳格であることに注意してほしい)。これを文脈の中で理解するために、例を示す。たとえば、平均値と同じ0.23というスコアだったものとして、たとえば次のようなものがある:
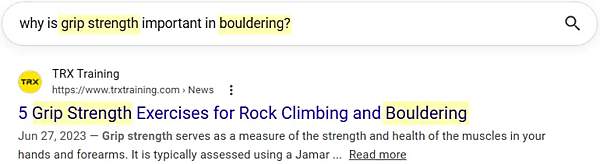
一致する単語をハイライトした。見てわかるように、この平均値は重複がかなり限定的であることを示している。
次は、ジャッカード類似度のスコアがより高いが(0.75)、完全一致ではない例だ:
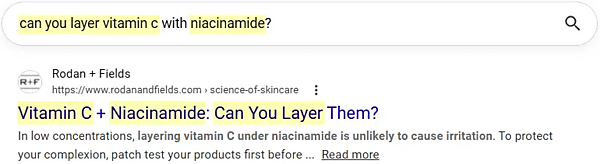
語順(ジャッカードでは完全に無視される)は別にして、これはかなり重複している。なお、真の完全一致であれば、ジャッカード類似度も1.0になる。
ベクトルデータのコサイン類似度のデータと例
→クエリ文字列と意味が一致しているか
データセット全体のコサイン類似度は平均で0.76だった。コサイン類似度は「文字列の比較」ではなく「意味で判断」するものなので、ジャッカード類似度よりはるかに柔軟だ(意味の解釈は利用したモデルによる)。
たとえば平均値と同じスコア0.76の例は次のようなものだ:
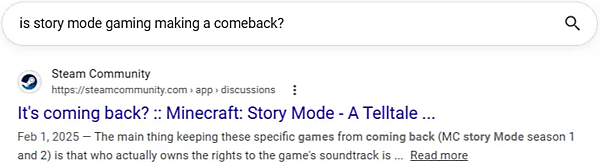
この例は興味深い。表示タイトルが、極めて構造化されたSEO型のタイトルだからだ。Minecraftに特化しており、検索ユーザーの意図とは少し異なるかもしれないが、意味的には確かに重複しているのがわかる。
次に、類似度の高い例を見てみよう。コサイン類似度が0.90だったものだ:
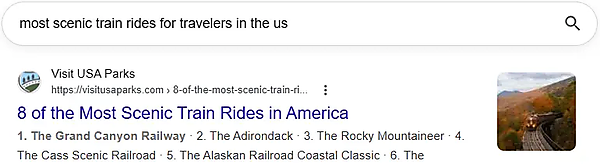
ベクトル埋め込みがおそらく「US」や「America」のような概念を同等と見なし、クエリとの関連性に影響しないわずかな違い(「8 of the」など)を無視しているのがわかる。
おまけ: 同じ単語は使われていないが、意味的な類似度は高いもの
すべての単語(の文字列)が完全一致していれば、すべての指標が1になる。ジャッカード類似度が高いということは、ほぼ常にコサイン類似度も高いということだ。では、「単語の重複は少ないが、意味的な重複が高い」ものはあったのだろうか?
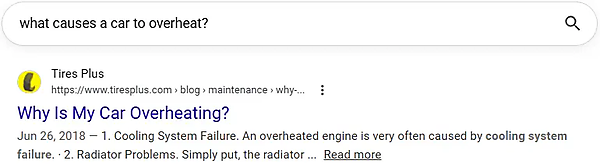
この組み合わせのコサイン類似度は0.91だが、ジャッカード類似度は0.10だ。「car」という単語だけが重複している。僕たち人間はこれら2つのフレーズが同じ意味だと簡単に判断できるが、より重要なのは、グーグルがこうした人間の直感を模倣する能力を高めていることだ。
※Web担編注 「overheat」と「overheating」の活用形をステミング/レンマ化すれば単語の類似度はさらに高まる。しかしここで筆者が強調したいのは「what causes(なにが原因で)」というクエリに対して「why(なぜ)」を同義だとグーグルが判断していることだろう。
別の例を挙げよう。コサイン類似度は0.82だが、ジャッカード類似度はゼロの場合だ。
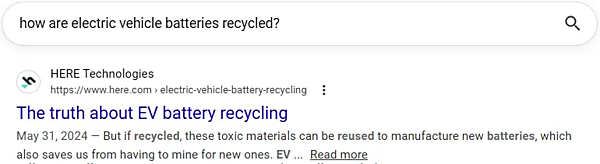
厳密に言えば重複している単語が1つもないが、単語のいくつかは元が同じ単語だ(「recycled」と「recycling」や、「batteries」と「battery」など)。とはいえ、「EV」が「電気自動車(Electric Vehicle)」を意味することは、人間ならばほぼ判断できるが、これまで機械には難しかった。
タイトルの意味的類似性を超えて、非常に興味深いことが起きている状況も発見できた。
「what causes a car to overheat?」(車がオーバーヒートするのはなぜか?)という例に戻って、3つのオーガニック結果を見てみよう。検索結果のタイトルではなくスニペットで、グーグルが太字強調している部分に注目してほしい(わかりやすいように色を付けて示している)。
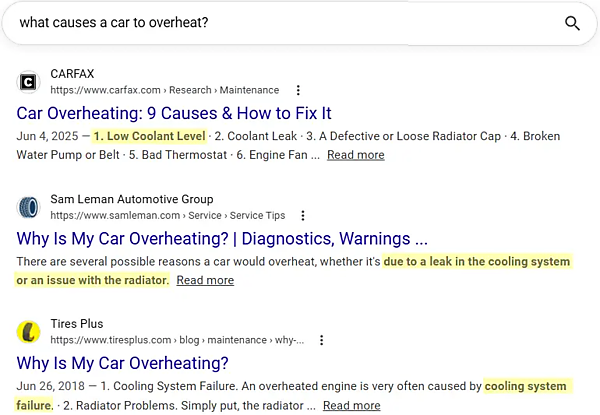
いずれのスニペットでも、強調されているのは「冷却システムの不具合」「冷却剤の漏れ・減少」を説明している部分だ。
グーグルはここで同義語や意味的類似性を認識しているだけでなく、回答になり得る情報を強調表示している。この強調表示は、結果を取得して表示された後に適用される処理だが、グーグルがどのような情報を優先しているかを把握するために、自分の検索結果で確認してみる価値はある。
2026年~2030年のキーワードターゲティング
キーワードは重要だが、キーワードスタッフィングが評価される時代は終わった(すばらしい!)。表示タイトルはグーグルが関連性を判断する要因のほんの一部に過ぎないが、今回の結果は僕たちの直感を裏付けている。その直感とは、「グーグルは部分一致や単純な同義語だけでなく、意味的類似性も理解する能力を高めている」ということだ。
ベクトル埋め込みとコサイン類似度を用いた意味的類似性は、単に便利な代用指標というわけではない。10年以上前からグーグル検索の仕組みに欠かせない要素であることは誰もが知っている。Geminiの検索基盤を支えるFastSearchにも組み込まれている。ベクトル埋め込みは、関連性を測定する手法の1つだ。
特定の指標に固執したり、それに合わせて過度に最適化したりすべきではない。しかし、これらの手法は「意味的な関係をグーグルがどのようにマッピングしているか」を理解し、関連性についてより柔軟に考えるのに役立つ。
こうした進化は検索ユーザーにとってもSEO担当者にとっても有益だろう。しかしキーワードターゲティングについては、もっと広い視野で見る必要がある。僕たちは、ごくわずかな完全一致のキーワードだけでなく、フレーズや意味が似ている広範なキーワード群にも対応できるようにコンテンツを作成(そして競争)している。検索がオーガニック検索と生成AIのハイブリッドになるにつれ、この傾向は加速する一方だ。この課題に対処するため、僕たちの手法や指標も進化する必要がある。
関連記事
Googleの「ヘルプフル コンテンツ アップデート」は失敗だった? 否、重要なことの始まりだ
2022年11月28日 7:00
Navboostクエリとは何か? グーグル流出文書からみえたSEOにおける意味と対策【後編】
2024年9月9日 7:00
検索エンジンがキーワードとページの“関連性”を算出する方法と、検索順位との関係
2014年1月6日 9:00
Googleの新しいSERP機能「他のユーザーも行った質問」を理解する5つのポイント(前編)
2019年12月16日 7:00
Google検索の強調スニペットをもっと知りたい! あなたの疑問に答える14のQ&A【チートシート無料ダウンロードあり】(前編)
2020年2月3日 7:00
AI世代の検索エンジンについていくための「セマンティック検索」「エンティティ」基礎入門 (前編)
2017年2月27日 7:00
バックナンバー
この記事の筆者
この記事は、Moz Blog に掲載された以下の記事を、Mozの許諾を得て日本語化したものです。

原文: 「How Much Do Keywords Matter in 2026?」 by Dr. Peter J. Meyers (2026/03/10)
筆者の人気記事
link rel="canonical"のようなURL正規化タグをSEOで有効活用するには
2009年3月5日 9:00
検索エンジンが順位を決める53の要因(39人のSEOプロが評価した重要度とコメント付き)
2007年10月1日 9:30
ホームページをGoogle検索に引っかからないようにする12の方法
2008年2月14日 9:00
サーチコンソールのHTMLタグはどこに? 所有権の確認など初心者ガイド
2015年11月9日 7:00
SEO基本技術のチートシート(トラの巻)を作ってみた
2008年6月9日 9:00
滅べばいいのにと思うSEOの10の迷信(都市伝説)
2010年6月14日 9:00





