グーグルのコア ウェブ バイタル導入は失敗だったと思うのだが ―― ウェブとCWVの現状【第1部】
「ページエクスペリエンスアップデート」と命名されたCore Web Vitalsの導入は、がっかりさせられるどころか、大きな失敗に終わったように思う。その理由をデータで示す。
2021年11月22日 7:00
Day 273: I am physically unable to tweet one more word about those damn Core Web Vitals
— Cyrus (@CyrusShepard) February 25, 2021
God have mercy on us all
第273日: あの、いまいましいCore Web Vitalsについて、もう一言もツイートできない
どうか僕たちに神の御慈悲を
頼むからこのまま読み進めてほしい。この記事では、
- Core Web Vitals(コア ウェブ バイタル)の何が悪かったのか
- 僕たちが現在どのような状況にあるのか
だけでなく、
- なぜまだCore Web Vitalsを気にする必要があるのか
を考える。
また、ここに至るまでのデータも示す。これらのデータでは、最低限のCWV基準に達しているサイトの数を、現在と当初の開始予定日の両方について示している。
この記事の執筆時点で、グーグルがまたしてもお決まりの「トリック」を使うことを明らかにしてから、1年半ほどが経っている。そのトリックとは、次のようなものだ:
グーグルの「トリック」 ―― 検索順位決定要因を事前に公表することで、僕たちがウェブを改善できるようにすること
公平を期すために言えば、これは(グーグルに極めて有利に働くとはいえ)全体として非常に崇高な目標だ。特に近年の「モバイルゲドン」やHTTPSのように、この時点ではよく練られた戦略でもあった。
これらの最近の例は、いずれも実際にその日を迎えてみると若干がっかりさせられるものだった。しかし「ページエクスペリエンスアップデート」と命名されたCore Web Vitalsの導入は、がっかりさせられるどころか、大きな失敗に終わったように思う。
この記事は3部構成のシリーズで、現在の状況と、それをどう理解し、次に何をすべきかを取り上げていく。
Core Web Vitalsはなぜ失敗なのか?
その根底にあるのは、導入の遅れだ。Core Web Vitalsに関するグーグルの動きは、次のようなものだった:
グーグルは当初(2020年5月の時点で)、アップデートを「2021年に実施する」と曖昧な言い方をしていた。
その後2020年11月には、グーグルは「2021年5月に実施する」とした。全体のリードタイムは異常に長いが、この時点までは順調だった。
驚いたのは2021年4月、アップデートを6月に延期すると発表したことだ。
その後6月になりグーグルは、「非常に長い時間をかけて」アップデートを開始した。
そして最初の発表から約16か月後の2021年9月初めになって、ようやくアップデートが完了したという発表があった。
では、僕がこの問題を取り上げるのはなぜか? それは、導入の遅れ(と、その過程でグーグルが繰り返した説明と矛盾)が、今回はグーグルの対応があまりうまくいかなかったことを示唆していると思うからだ。
グーグルは、Core Web Vitalsについて次のような意味あいで説明していた:
これは検索順位決定要因になる。だからウェブサイトのパフォーマンスを高めるべきだ。
しかし、理由が何であれ、僕たちは改善に動かなかっただろうし、いずれにせよグーグル側のデータは混乱していたので、同社はアップデートの重要性を「タイブレーカー」(他の条件がすべて同じだったときに用いる判断基準)レベルまで落とすしかなくなった。
これは企業やブランドにとって紛らわしく、混乱させるものであり、「何があろうとサイトのパフォーマンス向上に取り組むべきだ」という包括的なメッセージから注意をそらす要因になる。
ジョン・ミューラー氏が述べているように、「グーグルは結局のところ、検索を便利であり続けてるようにしたい」のだ。これこそ、グーグルが事前に発表するアップデートの根底にある虚勢だ。グーグルは、人々が検索結果に表示されると期待しているウェブサイトが表示されなくなるような変更はできない。
データはあるのか?
もちろんだ。僕たちが一体ここで、何をしているとお思いだろうか?
Mozが提供している非常に便利なグーグルアルゴリズム解析ツール「MozCast」については知っている人もいるかもしれない。MozCastは、競争力のあるキーワード1万件のコーパスをベースにしており、僕は5月、米国郊外のランダムな場所から、これらすべてのキーワードで上位20件に表示されるすべてのURLを、デスクトップまたはモバイルで見てみることにした。
検索結果は約40万件に上り、(驚くことに)最大21万件のユニーク(一意な)URLを含んでいた。
これらのURLのうち、この時点でCrUX(Chromeユーザーエクスペリエンス)データを得られたのはわずか29%だった。
CrUXデータは、Google Chromeで実際のユーザーから収集しているデータで、検索順位決定要因としてCore Web Vitalsの基礎となるものだ。
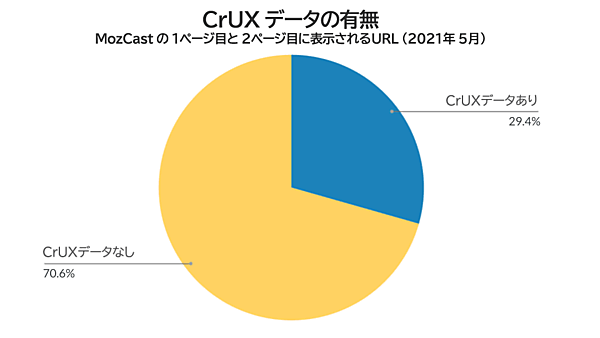
「CrUXデータがないURL」というのは、どういうことだろうか。グーグルがCrUXのデータを処理するには一定数のサンプルが必要だ(サンプル数が少ないと信頼できるデータにならない)。しかし、そもそもページビュー数の少ないURLでは、このサンプル数を満たすだけのChromeトラフィックがない。そうしたページは「CrUXデータがない」状態になる。
そうした事情はわかるのだが、この「1ページ目と2ページ目に表示されたURLのうち、CrUXデータがあったのは29%」という数字は、これらのURLが定義上ほとんどのページよりトラフィックが多いことを考えると(何といっても、競争力のあるキーワードで上位20件に表示されるくらいなのだから)、とりわけ情けないほど低い数字だ。
ではグーグルは、CrUXデータがないページのCore Web Vitals指標をどう判定しているのだろうか?
実際にはページの類似性に基づいて検索結果の一般化や推測を行っていることについて、グーグルはさまざまな表現で言葉を濁している。こうした手法は、ロングテールの大規模なテンプレート化されたサイトには有効だが、小規模なサイトにはあまり有効でないことが想像できる。
いずれにせよ、テンプレート化された大規模なサイトを手がけた僕の経験では、次のことを言える:
テンプレートが同じ2つのページでもコンテンツが違えば表示パフォーマンスは大きく異なることが多かった
一方のトラフィックのほうがはるかに多く、そのためキャッシュされるページの割合も総じて高い場合には、その傾向が特に強かった。
そうした迷宮入りしそうな問題は脇に置くとしても、Core Web Vitalsの導入にあたって、CrUXデータがある29%のURLに関してどのような状況だったのかと思う人もいるだろう。こんな感じだ:
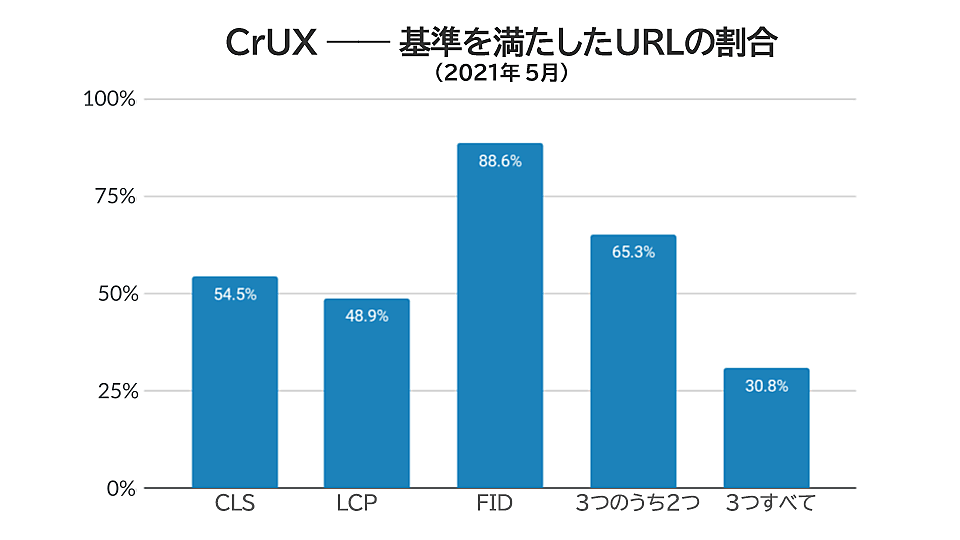
これらの統計値には印象的なものもあるが、ここでの真の問題は、「3つすべて」というカテゴリだ。
繰り返すが、グーグルは、パフォーマンスを押し上げるのに
- 3つの指標の基準をすべてクリアする必要があるのか
- あるいはどれか1つでもクリアすればいいのか
について、動画やツイートを含め矛盾した説明をしている。ただし、具体的な主張として、僕たちがこれらの基準を満たすよう努めるべきだとも述べており、現時点ではその基準に達していないという。
そもそも、データが得られた29%のURLのうち、すべての基準をクリアしたのは30.75%だった。「29%のうちの30.75%」は、全体の約9%に相当する。Core Web Vitalsをうまくやっていたと評価できるサイトは全体の9%ほどしかなかったわけだ。検索結果を大きく押し上げる変更を9%のURLに適用することは、グーグルの検索結果の品質にとってプラスにならないだろう。特に、除外される91%のなかには著名なブランドが多く含まれている可能性が非常に高いからだ。
アップデート開始時点までにどう変わっていたのか?
これが2021年5月の時点における状況であり、(僕の仮説では)グーグルがアップデートを延期した理由もここにある。では、アップデートがようやく始まった2021年8月の状況はどうだったのだろうか?
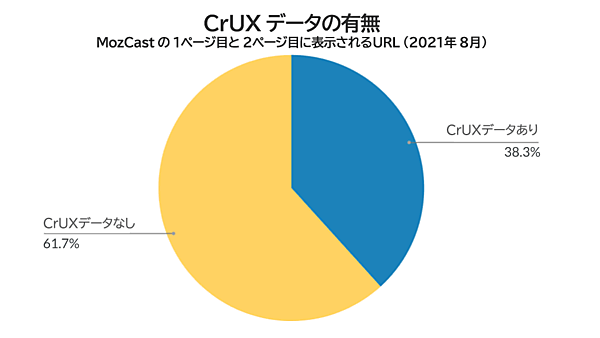

改めて(CrUXデータがある38%のなかの基準をクリアしていた36.3%を)計算し直してみると、全体の14%弱だ。以前の9%から著しく増加している。
グーグルがデータの収集量を増やしていることや、ウェブサイトが内容を集約していることも増加の要因だ。今後もこの傾向は強まるとみられ、グーグルは検索順位決定要因におけるCore Web Vitalsの重要度をさらに高められるようになるのではないだろうか。
これについては、第2部と第3部で詳しく取り上げる。
※Web担編注 第2回と第3回は少し後になる。間に他の記事が挟まるが、完成し次第お届けするのでお待ちいただきたい。
それまでの間、自分のサイトのCore Web Vitalsの基準値に対する現在の位置付けを知りたい人に向けて、Mozはそのためのツールを現在ベータ版で提供しており、2021年中に正式版をリリースする予定となっている。
付録
さらに深く掘り下げてみたいという人は、2021年8月のデータに基づく以下の分布図で、自分のスコアが業界全体で見るとどのへんに位置するのか確認してみよう。
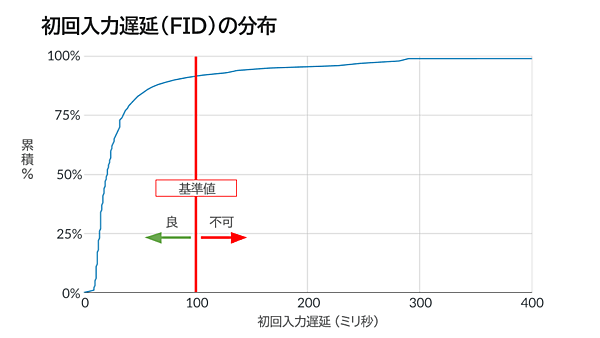
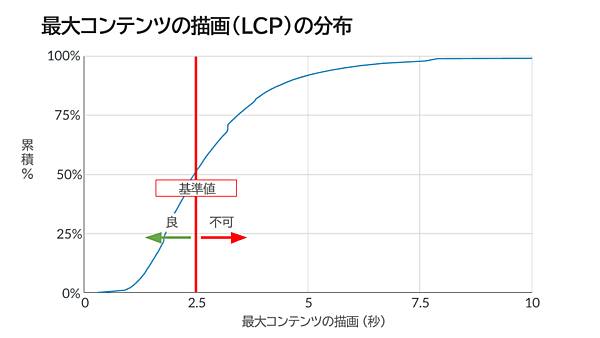
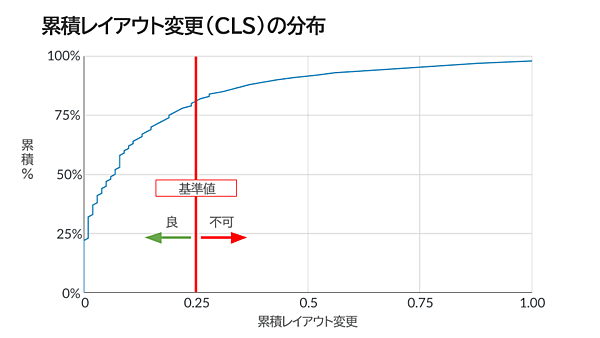
※Web担編注 この分布図ではCLSの状態を「良」とする基準値を「0.25」としているが、グーグルは基準値を「0.1」と示している(0.25はその値を超えると「悪い」とする基準値)
関連記事
コア ウェブ バイタルの3指標はどれも薄っぺらいと思うのだが ―― ウェブとCWVの現状【第2部】
2022年1月17日 7:00
【重要】コアウェブバイタルとは? LCP/FID/CLSをわかりやすく解説【SEO情報まとめ】
2020年6月5日 7:00
売上8%↑ PV 9%↑ 直帰率15%↓など、社内説得に使えるCWV改善のビジネス成果事例14連発【SEO情報まとめ】
2021年6月4日 7:00
コアウェブバイタル改善にはメリットしかない。離脱率24%減・トップニュース表示は魅力的【SEO情報まとめ】
2020年6月19日 7:00
グーグルが公式に「SEO的には、文字数300語以上・KW出現率2%以下」と示してプチ炎上【SEO情報まとめ】
2022年5月20日 7:00
Googleの「ヘルプフル コンテンツ アップデート」は失敗だった? 否、重要なことの始まりだ
2022年11月28日 7:00
バックナンバー
この記事の筆者
筆者の人気記事
link rel="canonical"のようなURL正規化タグをSEOで有効活用するには
2009年3月5日 9:00
検索エンジンが順位を決める53の要因(39人のSEOプロが評価した重要度とコメント付き)
2007年10月1日 9:30
ホームページをGoogle検索に引っかからないようにする12の方法
2008年2月14日 9:00
サーチコンソールのHTMLタグはどこに? 所有権の確認など初心者ガイド
2015年11月9日 7:00
SEO基本技術のチートシート(トラの巻)を作ってみた
2008年6月9日 9:00
滅べばいいのにと思うSEOの10の迷信(都市伝説)
2010年6月14日 9:00




