
このページは、外部サイト
CyberAgent SEO Information の情報をRSSフィード経由で取得して表示しているため、記事の一部分しか表示されていなかったり、画像などが正しく表示されなかったり、オリジナル記事が意図したデザインと異なっていたりする場合があります。
完全な状態のオリジナル記事は 「
Google Discoverに出ているものの特徴(3)」 からご覧ください。
さて、Google Discoverに出ているものの特徴の第3回です。
GoogleDiscoverに出ているものの特徴(1)
GoogleDiscoverに出ているものの特徴(2)
ちなみに第2回の記事のDiscover表示回数およびクリック数は、まさかの「0」です!笑
なんとなく心がああたり(仮説)が2つあるのですが、それは今回のものが出るか出ないかによってでして、その話はまた後日。
さてGoogleDiscoverに出ているものの特徴3回目は、"サイト"について関わる部分について見ていきたいと思います。
ここで言う"サイト"はGoogleがよく"ホスト"と呼ぶ「サブドメイン」だと考えて頂いて構いません。
グラフの見方は詳しくは1回目の記事をご覧いただきたいと思いますが、一番右がGoogle Discoverの特徴、それ以外はInformationalクエリにおける通常検索結果の左から5位刻みの箱ひげ図となっています。
サイト全体のindex数とGoogle Discover

サイト全体のindex数≒サイトの規模と言っても良いと思いますが、通常の検索結果に比べてDiscoverは大きなサイトが出ていることが分かります。
Yahoo!ニュースはじめ大きなニュースサイトやニュースポータルが出ていることが大きいとは思いますが、大規模サイトのほうが信頼性が高いと見ている可能性もあると思います。
サイト内のキーワードを含むページ数とGoogle Discover

サイト内のキーワードをtitleに含むページ数とGoogle Discover

さて同じようなグラフが2つ並びました。
これは、サイト内におけるそのトピックの厚みを表すような指標になると思います。
「渋谷スクランブルスクエア」がトピックワードであれば、前者が「渋谷スクランブルスクエア」が含まれているページが何ページあるか?で、後者が「渋谷スクランブルスクエア」を<title>タグに含むものが何ページあるか?を見ています。
ページ全体に含まれているものを見ているのと<title>に含まれているものを見ていることからY軸の数値が異なります。
通常検索でもある程度これらの数値が大きいほうが優位になっている傾向がありますが、Discoverの場合はそれよりも大きい数値になっている、つまりそのトピックに対してサイトとして厚みがあるものがよく出ている傾向になります。
「渋谷スクランブルスクエア」のコンテンツが1ページだけのものよりも100ページ持っているもののほうが多く出ている傾向にあるということです。
もちろん、大規模なサイトが出やすいということから相関しただけと考えられなくもありませんが。
サイト内のキーワードをtitleに含むページの比率とGoogle Discover

先の"サイト内にキーワードをtitleに含むページ"がサイト全体に対してどのくらいの割合あるかというものを出してみました。
そのトピックの濃度みたいな話でしょうか?
サイト全体が「渋谷スクランブルスクエア」の話題なのか?それとも数多ある「渋谷」の話題の中のひとつとして「渋谷スクランブルスクエア」があるのか?ということになります。
通常検索でも若干濃度が濃いほうが上位になりやすい傾向にありますが、Disocoverは中央値が上がっていることを見ると若干ですが濃度が濃いほうが出ているものが多くなる傾向にはあります。
ただし、数値的には1%にも見たいない差のため気にするレベルではないかもしれません。
率を考えるよりも先にあったような数で考えるほうが良いでしょう。
これはオーガニック検索においても同じことですが、そのトピックに対してどれだけ網羅的で詳しく役立つコンテンツが提供できているかということに尽きると思います。
ドメインエイジとGoogle Discover
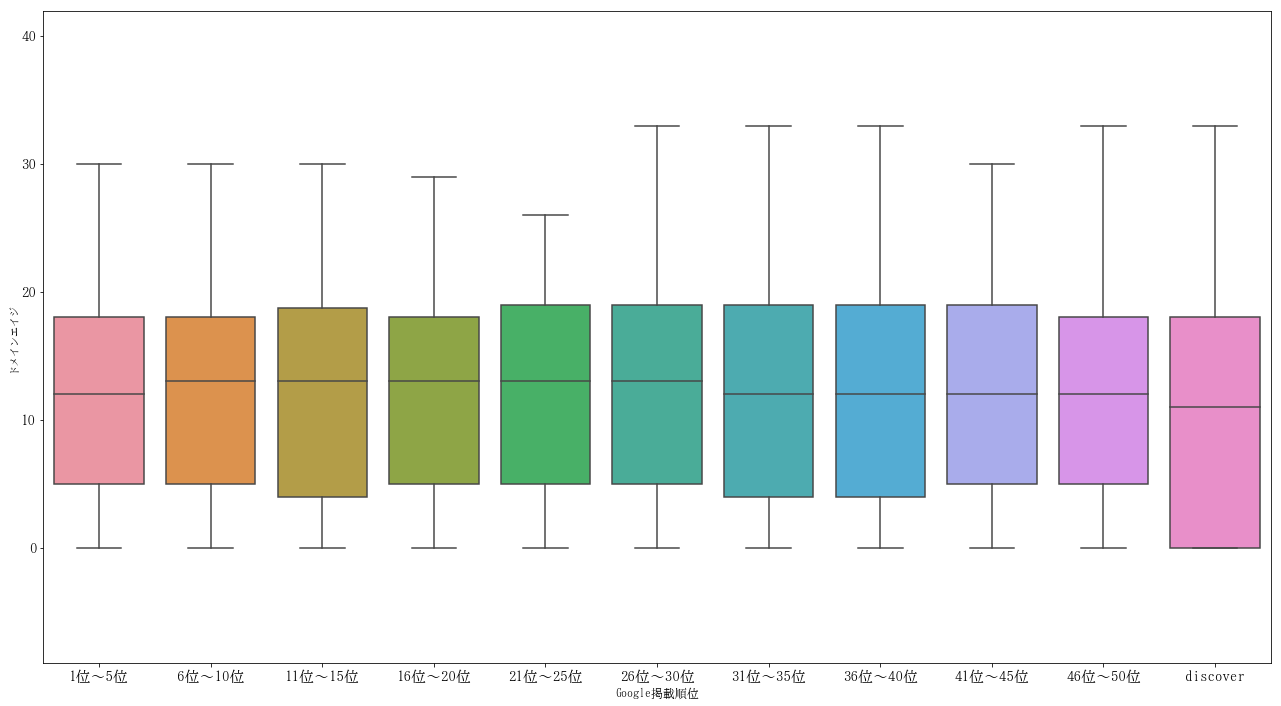
【朗報】な人もいるかもしれないですが、ドメインエイジとは相関がありませんでした。
通常検索でも「ドメインエイジが長いほうが優位に働く」というふうに言う人もいますがこれらはGoogleが否定しています。ドメインエイジが長いサイトのほうがリンクやサイテーションが集まっていて、もしくは集まりやすくてということはあると思うのでまったく間接的にも関係しないとは言えないと思いますが。
Discoverにおいては若いドメインも出てきているようです。
サイト規模が大きい方が有利とかサイテーションが多い方が良いとか被リンクがサイト全体に多い方が良いとか(第2回の記事参照)、そういう部分では若いドメインよりも歴史あるドメインのほうが蓄積されやすいと思いますが、新しいサイトだからと言って出すことが不可能なわけではないようです。
httpsとGoogle Discover
よくわからないグラフになりましたが、線がY軸「1.0」のところに集中しています。
httpsなら1、httpなら0になるようにしています。
見ての通り全部「1.0」です。
通常検索でも5位以内は現在ほとんどがhttpsになっています。
当然のようにDiscoverについても「1.0」です。
データ上ではDiscoverはhttps率100%でしたし、私のスマートフォンで見ても現時点ではhttps率100%でした。
いまのご時世、httpに好んでするケースはないと思いますが、まだ粘っている方は早めに変えたほうが良いとは思います。(某大学はいつhttpsにするのだろうか・・・・)
まとめ
ということで今回はサイト全体の作りのような部分とGoogleDiscoverの関係を見てみました。
前回の外部要因のところでInformationalクエリではなくてTransactionalクエリの特徴に近いことをお伝えしたと思いますが、実は今回のものもその傾向が強くなっています。
サイト規模が大きいもの、トピックに厚みがあるもの(そのカテゴリの商品が多いECサイトが有利という理論)などはまさにそれです。
とは言え、Transactionalクエリどうこう意識するよりも、そのトピックにおいて1ページでなんとかしようとするのではなく、サイトとして詳しい役立つ状態になることを目指すべきではないかと思います。
次回たぶん最終回ですが、ページの作りとDiscoverの関係性をお伝えしたいと思います。
@kimuyan
なお、サイバーエージェント広告事業本部のSEOコンサルティングに興味がおありの方は、
こちらからお問い合わせください。


