このページは、外部サイト
Google ウェブマスター向け公式ブログ の情報をRSSフィード経由で取得して表示しているため、記事の一部分しか表示されていなかったり、画像などが正しく表示されなかったり、オリジナル記事が意図したデザインと異なっていたりする場合があります。
完全な状態のオリジナル記事は 「
画像検索についての A to Z」 からご覧ください。
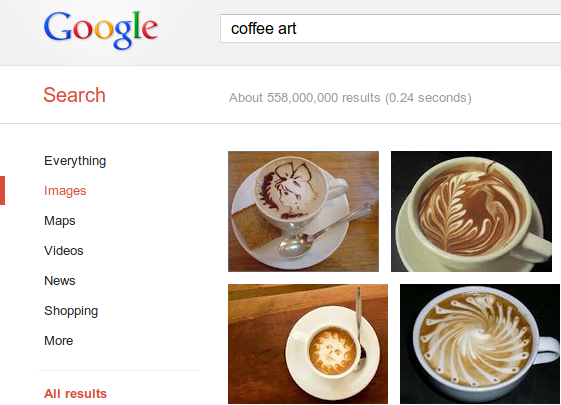
創造性は私たちの生活に大切なもので、日々の暮らしに豊かさを与えてくれます。たとえば、友人のために見た目も楽しいラテアートを作ってあげたいけど創造的で素敵な絵柄が思いつかない。そんなとき、私が利用するのが
Google 画像検索 です。
検索結果に表示される画像は、ブロガーや情報サイト、写真素材サイトなど、大小さまざまな規模のサイトオーナーが、自分の HTML ページに埋め込んでいる画像です。Google は、BMP、GIF、JPEG、PNG、WebP、SVG といった形式の画像をインデックスに登録しています。
しかし、Google はどうやってこれらの画像が紅茶ではなくコーヒーであることを認識しているのでしょうか?Google のアルゴリズムは画像をインデックスに登録するとき、その画像が見つかったページのテキストを見て、画像に関する情報を得ています。それ以外にも、ページのタイトルや本文も見ています。画像のファイル名や、リンク先を示すアンカーテキストや「
alt 属性のテキスト(英語)」から情報を得ることもあれば、コンピューター ビジョンを用いて画像情報を得たり、ページ上にキャプション テキストが存在するときは
画像のサイトマップ に含まれているキャプションの情報を用いることもあります。
画像をインデックスに登録しやすくするために、下記の点を守ってください。
- 画像が埋め込まれている HTML ページと画像そのもの、どちらも Google がクロールできるようにしておくこと
- Google が対応している形式の画像であること(BMP、GIF、JPEG、PNG、WebP、SVG)
さらに、下記のようにしておくこともおすすめします。
- 画像のファイル名が画像の内容に関連した名前になっている
- 画像の alt 属性が、人間が読んで分かるような画像説明になっている
- 加えて、HTML ページのテキスト コンテンツと画像近辺のテキストを、画像に関連した内容にしておくことも有効です。
ここからは、これまでに画像検索について寄せられた質問に対してお答えします。Q: Googlebot-Image ではなく、Googlebot が画像をクロールしているのを見かけることがありますが、それはなぜですか?
A: URL のリンク先が画像なのかどうか不明なときによくある現象です。こういった場合、Google はまず Googlebot で URL をクロールします。URL のリンク先が画像だと分かれば、通常 Googlebot-Image で再び訪問します。したがって、通常は Googlebot と Googlebot-Image の両方に対して、画像とページのクロールを許可しておくとよいでしょう。
Q: 画像にファイル サイズに上限があるというのは本当ですか?
A: Google では、どんなサイズの画像でもインデックス登録します。ファイル サイズに制限はありません。
Q: 画像に含まれている EXIF や XMP などのメタデータはどうなりますか?
A: ユーザーがより簡単に検索対象にたどり着けるようにするため、Google は見つけたあらゆる情報を使用します。なお、EXIF データなどの情報は、画像をクリックしたときに表示されるページ(インタースティシャル ページ)の右側のサイドバーに表示されることがあります。
Q: 画像のサイトマップは送信すべきでしょうか。どんな利点があるのですか?
A: はい、送信してください。
画像のサイトマップ は、Google に新しい画像の存在を知らせるのに役立つと共に、画像が何の画像なのかを知る助けにもなります。
Q: CDN を使って画像を提供しています。どうやったら画像のサイトマップを使用できますか?
A: クロスドメインの制約(英語)は、サイトマップのタグに対してのみ適用されます。画像のサイトマップでは、タグは別のドメイン上の URL を示すことが可能ですので、画像に CDN を用いていても大丈夫です。Google がクロール エラーを発見した場合にお知らせできるよう、ウェブマスター ツールにて CDN のドメイン名を検証することもおすすめします。
Q: 自分が所有する複数のドメインまたは複数のサブドメイン上(例えば CDN や関連サイトなど)に画像が重複して存在する場合は、問題となりますか?
A: 一般的に、どのタイプのコンテンツでも複製しないことが最善の方法です。複数のホスト名にまたがって画像を重複させている場合、Google のアルゴリズムはその中の 1 つをその画像の優先(canonical)コピーに選びますが、それが皆さんの選んでほしいバージョンであるとは限りません。またその場合、画像のクロールやインデックス登録が遅くなることもあります。
Q: 元々の画像が、それ以外のソースのものよりランキングが下位になっている場合がときどきありますが、それはなぜですか?
A: Google は画像の内容を判定する際に、ページのテキスト コンテンツを使用していることを覚えておいてください。例えば、オリジナル ソースが、テキストがほとんど存在しない画像ギャラリーのようなページである場合、テキストをより多く含むページが上位の検索結果として選ばれることがあります。ある特定の検索キーワードに対する検索結果があまりにもおかしいと思われる場合は、検索結果の下に表示されているフィードバック用リンクで報告するか、
ウェブマスター ヘルプフォーラム にて事例を報告してください。
セーフサーチユーザーがセーフサーチ フィルターをオンにしている場合、Google のアルゴリズムは様々なシグナルに基づき、ある画像(ウェブ検索の話であれば、ページ全体)を検索結果から除外すべきかを判定しています。画像の場合、そういったシグナルの一部はコンピューター ビジョンを使って生成されていますが、セーフサーチ アルゴリズムでは、もっとシンプルなこと、例えばその画像が以前どこで使用されたのかや、画像が使用されていたコンテキスト(文脈)なども見ています。
ただし、最も強力なシグナルの 1 つは、自発的にマークされたアダルト ページです。アダルト コンテンツを配信するウェブマスターの方は、下記のいずれか 1 つのメタタグでページをマークアップすることをお勧めします。
<meta name="rating" content="adult" />
<meta name="rating" content="RTA-5042-1996-1400-1577-RTA" />
ユーザーの多くは、検索結果にアダルト コンテンツが表示されることを好みません(子供が PC を使用する場合は特にそうです)。上記メタ タグのいずれかをウェブマスターが用いることで、ユーザーは見たくない検索結果や、想定外の検索結果を見ずに済むので、ユーザー エクスペリエンスの向上につながります。
どんなアルゴリズムにも当てはまりますが、セーフサーチ フィルターによってコンテンツが検索結果から意図せずして除外されてしまうことがあります。ご自分の画像やページがセーフサーチによって誤って除外されていると思われるときは、
こちらのフォーム (英語)を使ってご連絡ください。
画像のインデックス登録について詳しくは、
画像 に関するヘルプセンターの記事や、役立つ情報が満載の
検索エンジン最適化 (SEO) スターターガイド を参照してください。質問などがございましたら、
ウェブマスター ヘルプフォーラム までお寄せください。
Written by Gary Illyes, Webmaster Trends Analyst
Original version:
1000 Words About Images