※この記事は読者によって投稿されたユーザー投稿のため、編集部の見解や意向と異なる場合があります。
また、編集部はこの内容について正確性を保証できません。
また、編集部はこの内容について正確性を保証できません。
日本語のサイトを多言語に翻訳する際に、まず日本語の原稿を揃える作業がありますが、原稿が存在しないで、画像中のテキストしか残っていない、というようなことが良くあります。最近ではブラウザのプラグインなどでOCRのツールも多くあり、人によって使いやすいものは違うかもしれませんが、個人的にオススメのGoogleドライブを使ったテキスト抽出方法をご紹介したいと思います。
抽出方法
1)テキストの入った画像をGoogleドライブでアップします。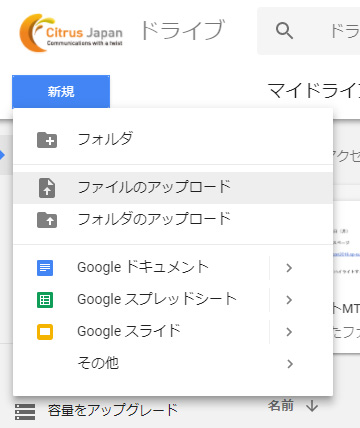
2)このように、アップされた画像が表示されます。
3)プレビューウィンドウを一旦閉じて、アップしたファイルを右クリック。「アプリで開く」から「Googleドキュメント」を選択します。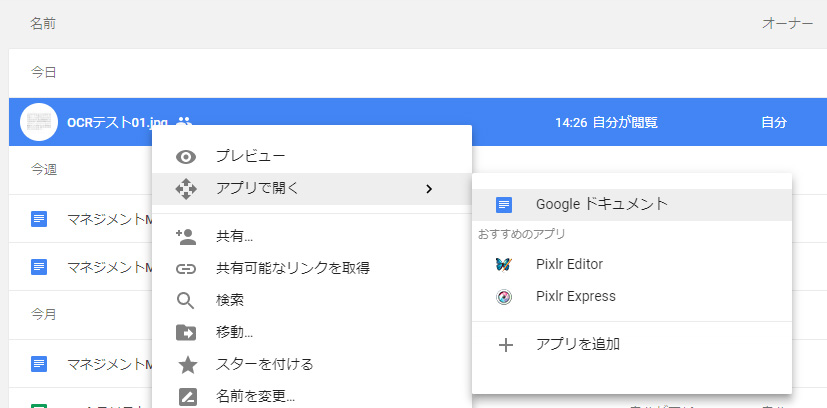
4)Googleさんが、くるくる少し考えた後に、画像の下に抽出されたテキストが表示されます。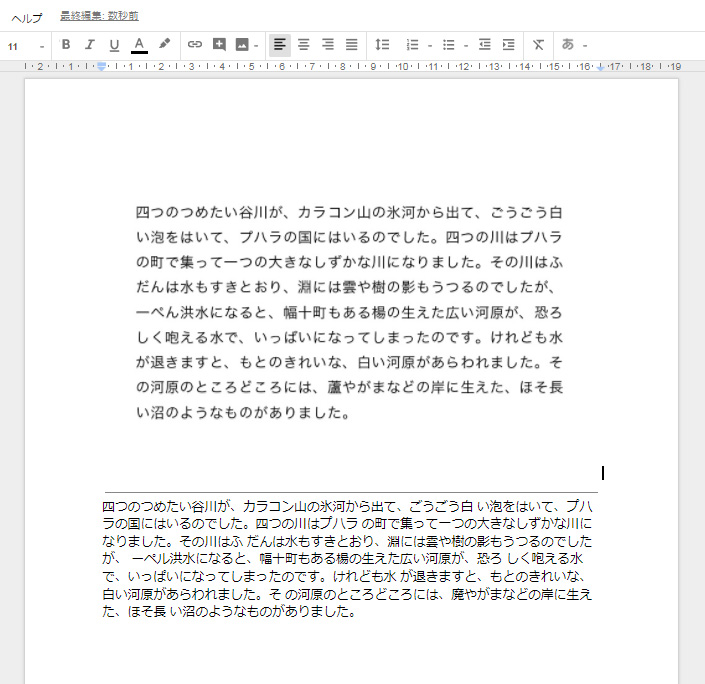
これは便利!!
ん? でもよく見ると・・・ちょっと怪しいですね。
▼詳しくはこちら▼
筆者の人気記事




