ELYZAが画像生成技術を応用した日本語拡散言語モデル公開、高速生成で電力削減に期待
商用利用可能な「ELYZA-LLM-Diffusion」、文章を左から右へ逐次生成せず速度が向上
1月19日 7:02
大規模言語モデル(LLM)の研究開発・社会実装のELYZA(イライザ)は、日本語における知識・指示追従能力を強化した拡散大規模言語モデル(dLLM)「ELYZA-LLM-Diffusion」シリーズを開発し、商用利用できる形で公開したと1月16日に発表した。KDDIのAIモデル開発向けGPU基盤を活用した。モデルの公開に併せてデモも公開している。従来とは異なる生成手法を採用しており、推論の効率化や生成速度の向上、消費電力の低減が期待されている。

dLLMは、主に画像生成AIで用いられてきた「拡散モデル」の手法を言語生成に応用したAIモデル。従来の主流だった自己回帰モデル(ARモデル)のように、テキストを左から右へ一文字ずつ順番に逐次的に生成するのではなく、dLLMは段階的にノイズを除去することでテキストを構成する。この方法によって、設計次第でより少ない処理回数で文章生成が可能になるので、将来的に電力効率に優れた高性能なAIを実現する技術として注目を集めている。
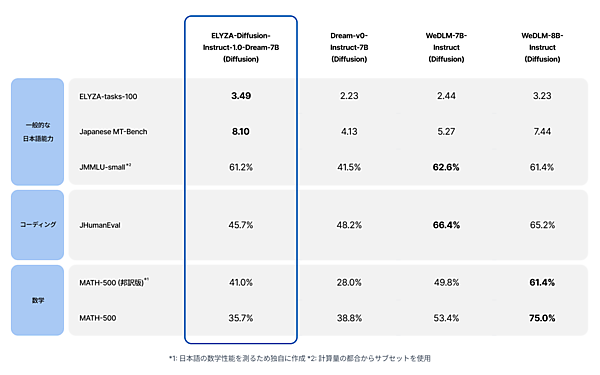
日本語データで追加事前学習したベースモデル「ELYZA-Diffusion-Base-1.0-Dream-7B」と、指示学習した「ELYZA-Diffusion-Instruct-1.0-Dream-7B」の2種類を公開した。香港大学の自然言語処理研究グループ(HKU NLP Group)が公開したdLLM「Dream-org/Dream-v0-Instruct-7B」をベースに日本語データによる学習を重ねることで、一般的な日本語能力を問われるタスクにおいて、既存のdLLMと同等かそれ以上の性能を実現したという。
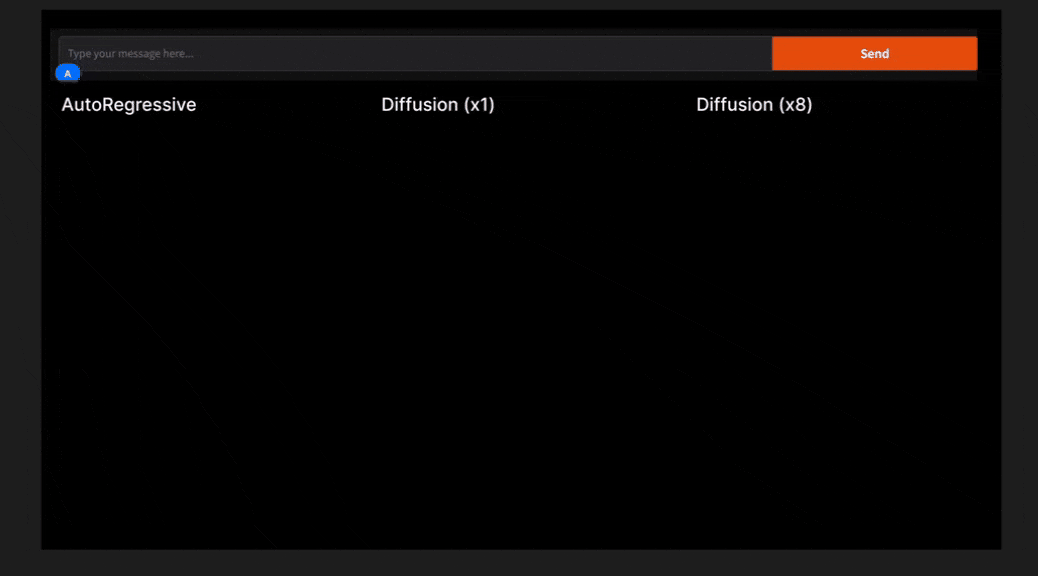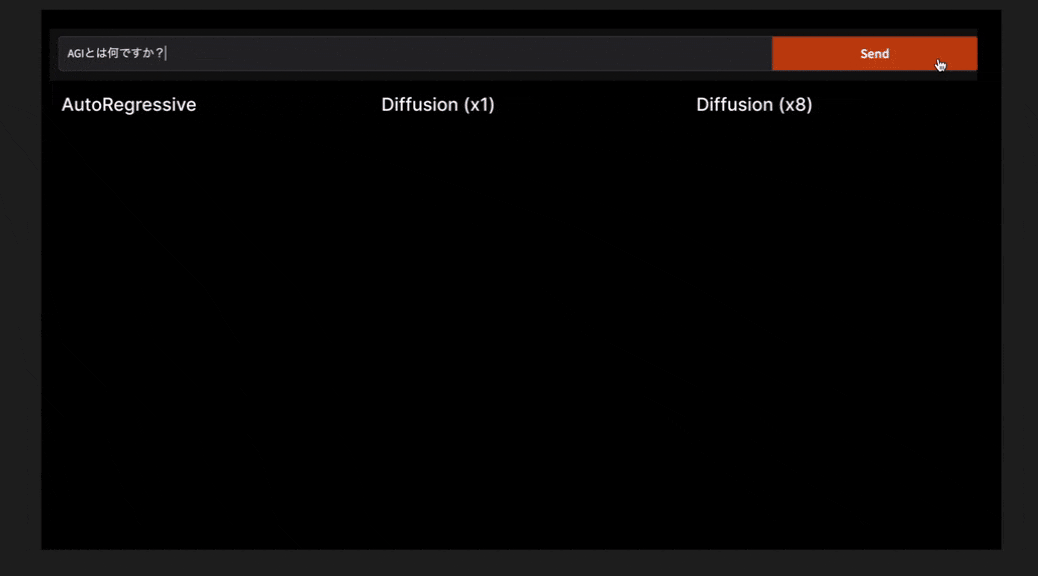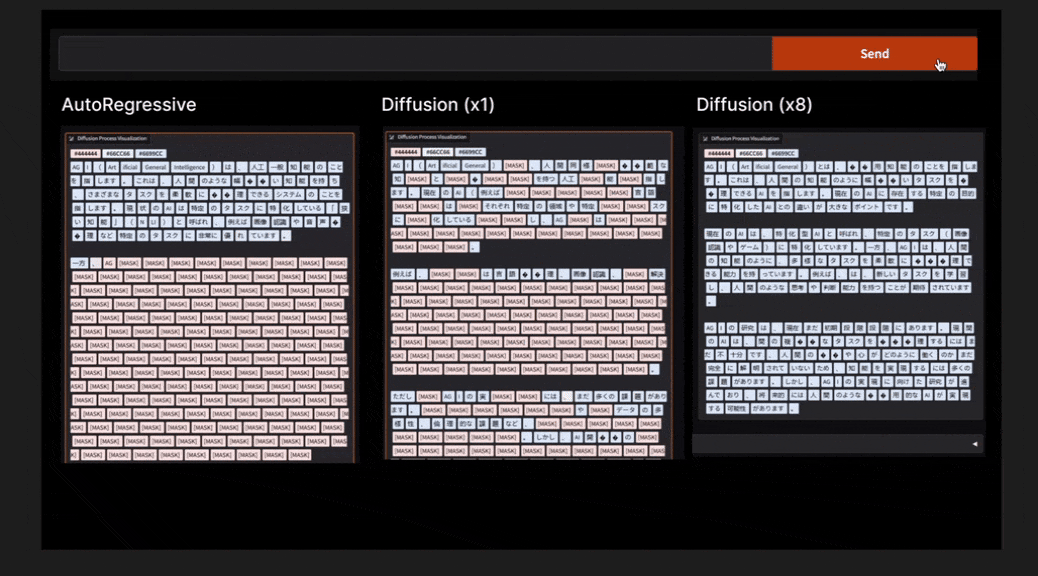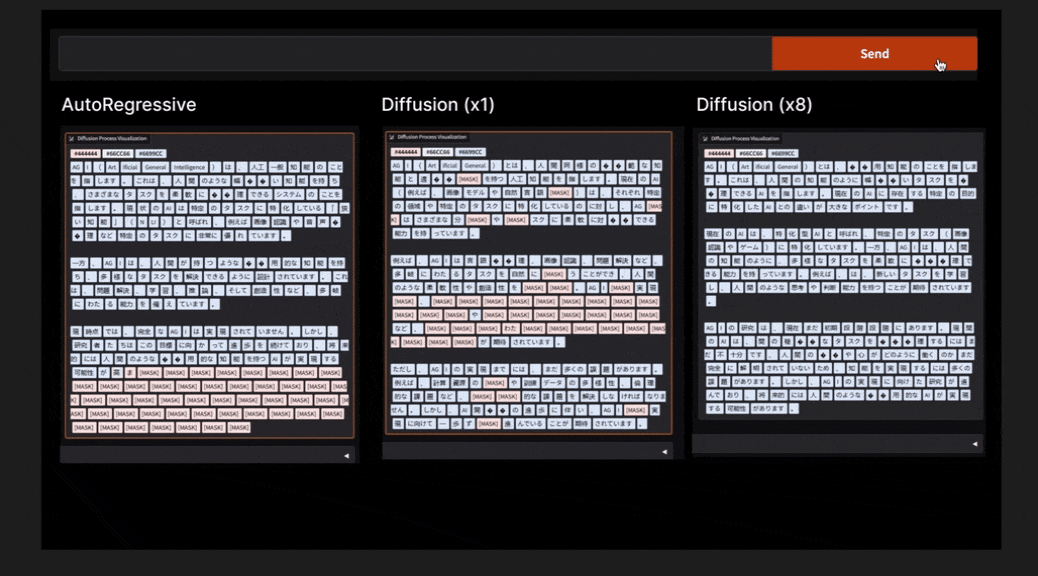
開発の背景には、世界的な社会問題となっているAI活用による電力消費量の増加がある。ELYZAは、少ない処理回数で生成可能なdLLMの研究を進めることで、電力効率の良い高性能な日本語LLM開発を加速させることができると期待している。今後もLLMを中心とした最先端の研究開発に取り組み、研究成果を公開・提供することで、国内におけるLLMの社会実装の推進と、自然言語処理技術の発展を支援していく。
この記事の筆者

筆者の人気記事
国民生活センターが道交法の基準上限を上回る「電動アシスト自転車」を新たに公表
2023年9月11日 7:02
イオンが「電子マネーWAONポイント」を「WAON POINT」に統合、分かりにくさ解消
2025年11月12日 7:03
アマゾンジャパンが「インボイス制度」に対応、販売事業者に代わって適格請求書を発行
2022年10月28日 7:03
総務省が「Pinterest」「Amebaブログ」「爆サイ.com」「ニコニコ」を情プラ法で指定
2025年6月3日 7:03
「後払い決済サービス」のトラブルが3年間で3倍に急増、国民生活センターが注意喚起
2025年7月3日 7:02
「Yahoo!メール」が3月から新ドメイン「@ymail.ne.jp」のメールアドレス提供開始
2022年2月28日 7:01




