GooglebotはHTMLの先頭2MBしか読まない。長大ページのサイトは要注意?【SEOまとめ】
「GooglebotがHTMLを2MBしか読まなくなった」と、SEO関係者のあいだで騒動になっている。新たな制限なのか? その背景は? インデックスへの影響の調べ方は? 詳しく理解しておこう。
2月13日 7:05

「GooglebotがHTMLを2MBしか読まなくなった」と、SEO関係者のあいだで騒動になっている。新たな制限なのか? その背景は? インデックスへの影響の調べ方は? 詳しく理解しておこう。
コーナーの更新に少し間があいてしまったが、今回も皆さんの役に立つ情報をまとめてお届けしている。SEOとAIに詳しくなるための情報を、ぜひチェックして学んでほしい。
- GooglebotはHTMLの先頭2MBしか読まない。長大ページのサイトは要注意?
- AEO/GEOは「SEOの拡張」――2026年に向けてマーケターが知るべき本質と新指標
- AIの台頭により「情報提供型コンテンツ」はもうSEOで通用しないのか?
- 独立系SEOコンサルタントになるための5つのステップ
- 純度100%のAI生成コンテンツは2026年も短い命
- Bing WMTに新指標? Copilotの引用状況がわかる「AI Performanceレポート」登場か
- Google Search ConsoleにもAIレポートが追加される可能性あり? グーグル社員が匂わせ発言!?
- グーグルのウェブスパム対策と検索品質にAI検索が与える影響
- 米ヤフーも生成AI検索市場に参入、その名も「Yahoo Scout」
- インスタグラムで最も反応をとれる投稿時間帯は? 960万件の投稿分析で最適な投稿タイミングが判明
- AI OverviewとAI Modeが連携、AIO→AIMへと継ぎ目なく追加質問できるように
- AIトラッキングツールは一貫性に欠け信用できない? ChatGPTやGoogle AIが同一ブランドを2回推薦する確率は100分の1未満
今週のピックアップ
GooglebotはHTMLの先頭2MBしか読まない。長大ページのサイトは要注意?
実は以前からそう。Googlebotには独自設定 (グーグル検索セントラル) 国内情報
検索用のGooglebotは、HTMLの先頭から2MBしか読まない。
グーグルの公式ドキュメントではずっと「先頭の15MBまで読み込む」と記載されてきたのだが、ドキュメントの記述が「HTMLなどのテキスト系コンテンツは2MBまで」と変更された。
- 最新版のGooglebot関連ドキュメント(2026年2月3日更新)
- そのドキュメントの過去のバージョン
- 一般的なクローラーではなくGooglebotが15MB読み込むことを明示する公式ブログ記事(2022年)
実際に巨大サイズのURLをインデックスさせて2MB制限があることを確認したブログ記事も公開されている。
ただし、「新たに制限が厳しくなって2MBに絞られた」というわけではない。グーグルの中の人に確認したところ、「昔からずっと15MB制限ではなく2MB制限だった」という説明があった。つまり、今回のドキュメント修正は「記述内容が間違っていたので修正した」というものだ。
どうやら、このあとで説明する「一般的なグーグルのクローラーの制限」と「Googlebot特有の制限」が、グーグルの公式ドキュメントに正しく反映されていなかったというのが正しい状況のようだ。
そうしたグーグルの内情はこのあとで説明するが、まず2MB制限をどう解釈して対応すべきかを解説しておこう。
「2MB制限」と言っても、世の中の大半のサイトでは影響がないと思われる。というのも、2MBは「ページ表示のために読み込んだリソースの合計」での制限ではなく、「HTMLやJavaScriptのファイルごと」のサイズ制限だからだ。HTML内で指定されて読み込まれるCSSやJavaScriptファイルには、個別の上限(2MB)がそれぞれに適用される。
2025年の調査では、平均サイズは次のとおりだった:
| デスクトップ向け | モバイル向け | |
|---|---|---|
| HTML | 22KB | 22KB |
| CSS | 82KB | 77KB |
| JavaScript | 697KB | 632KB |
つまり、「平均の100倍ぐらいのコンテンツサイズがなければ、だいたいは問題なし」ということだ。
ただし、注意が必要な場合もある。次のようなサイトやページは、もしかしたら2MBを超えたサイズになってしまい、グーグルのインデックスに全文が反映されない状況が発生しているかもしれない:
- JavaScriptやCSSをインラインで大量に記述しているページ
- 画像などの情報を、HTML内のimg要素やインラインCSSでURL参照するのではなく、data-uriで直接ドキュメント内に指定しているページ
- 日本語で70万文字以上あるページ
- SPAでバンドル後のJavaScriptファイルサイズが大きい場合
- CMSのデバッグ出力が有効になっていて、HTMLコメントの形でデバッグ情報が大量に出力されてしまっている場合
不安な場合は、実際のページを表示しながらDevToolsで確認できる。Chromeで確認する場合の方法は次のとおりだ:
- Chromeで調査したいページを開いておく。
- [F12]キーを押して、DevToolsを開く。
- DevToolsの[ネットワーク]タブに切り替え①、[キャッシュを無効化]がオンであることを確認し②、フィルタを[すべて]にしておく③。
- さらにDevTools右上の歯車アイコン(2つあるので下のほう)をクリックして④上部設定バーを開き、[大きなリクエスト行]にチェックを入れる⑤。
- Chromeでページをリロードする。
- ページ表示のために発生したネットワークリクエストがDevToolsの[ネットワーク]タブに表示される。
- DevToolsの[ネットワーク]タブで、表見出しの[Size]をクリックしてサイズの大きな順に並べ替え⑥、大きいものを確認していく⑦。
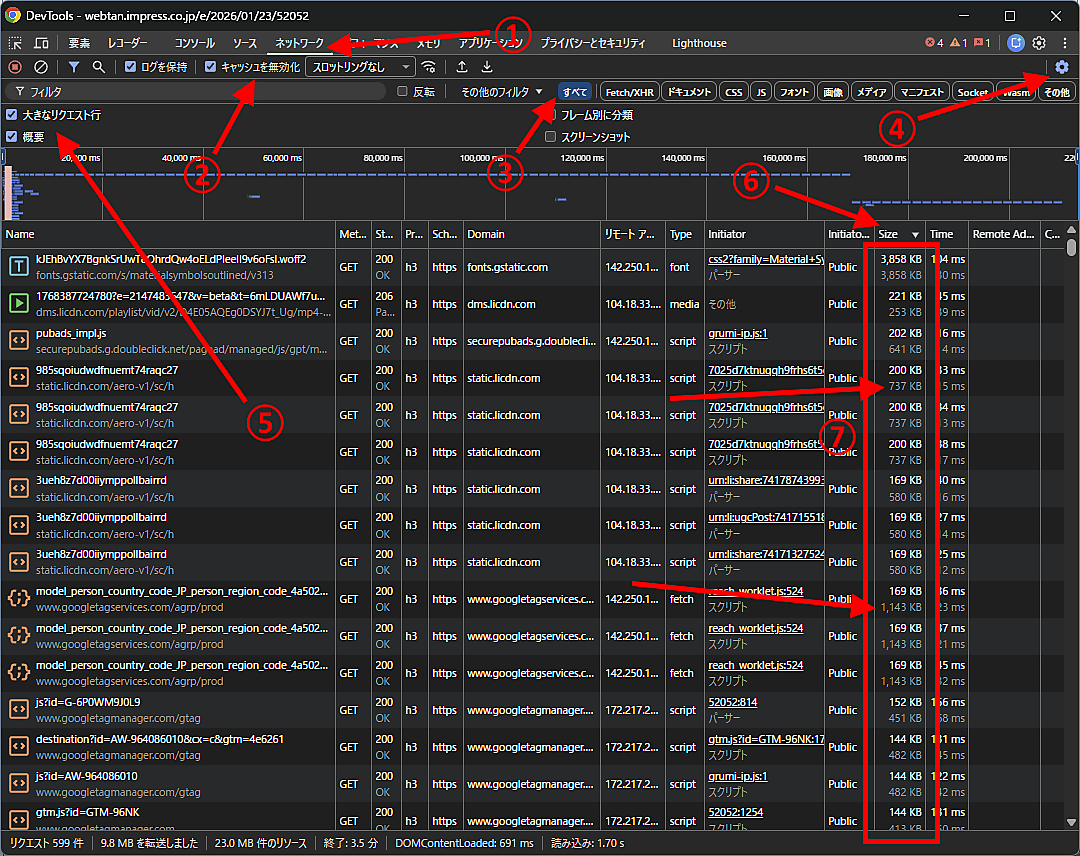
サイズの情報は2つずつ表示されるが、確認するのは下の数値だ(上の数値はネットワーク転送サイズで、下の数値がコンテンツサイズ)。並べ替えはネットワーク転送サイズを基準にするので、ある程度はリストの下のほうまで確認していくといいだろう。
ここで2,048KBを超えるものがあった場合は、その内容のすべてをGooglebotが読み込むわけではないということだ(動画・画像・フォントなどの非テキスト系コンテンツは大きくても問題ない)。
背景を解説しよう。どうやら、「グーグルの運用しているクローラー全般の制限」と「そのなかでもGooglebot特有の制限」があり、ドキュメントに正しく反映されていなかったようだ。
グーグルが更新したのはクローラーとフェッチャーが取得するファイルサイズの上限に関するドキュメントと、Googlebotに関するドキュメントだ。
※筆者補足:「クローラー」はウェブコンテンツを取得するプログラム。ウェブページを取得するGooglebotや画像を取得するGooglebot-Imageなどが該当する。「フェッチャー」は、ユーザーのリクエストに基づいて特定のURLにアクセスするツールおよびサービスの機能の一部。Search Consoleでサイト確認する際にアクセスするGoogle-Site-Verificationや、ユーザーの指示を受けてNotebookLMがURLにアクセスする際のGoogle-NotebookLMなどが該当する。
Google のクローラーとフェッチャー(ユーザー エージェント)の概要を説明するドキュメントでは、次のセクションが新たに追加された:
ファイルサイズの上限
Google のクローラーとフェッチャーは、デフォルトでは、ファイルの最初の 15 MB のみをクロールします。この上限を超えるコンテンツは無視されます。プロジェクトごとに、クローラーとフェッチャー、およびさまざまなファイルタイプに対して異なる上限を設定できます。たとえば、Googlebot のようなクローラーに対して、HTML よりも PDF のファイルサイズの上限を大きくすることができます。
Googlebotを解説するドキュメントの「Googlebot がサイトにアクセスする方法」セクションのクロールするファイルの上限に関する段落は、次のように更新された。
Google 検索のクロールでは、Googlebot はサポートされているファイル形式の最初の 2 MB と、PDF ファイルの最初の 64 MB をクロールします。レンダリングの観点から見ると、HTML で参照される各リソース(CSS、JavaScript など)は個別に取得され、各リソースの取得には、他のファイル(PDF ファイルを除く)に適用されるのと同じファイルサイズの制限が適用されます。
上限に達すると、Googlebot はフェッチを停止し、すでにダウンロードされたファイルの一部のみをインデックス登録の対象として送信します。ファイルサイズの上限は、非圧縮データに適用されます。Google の他のクローラー(動画用 Googlebot、画像用 Googlebot など)では、異なる上限が存在する場合があります。更新前は次のようだった(強調した箇所が顕著な違い)。
Googlebot は、HTML ファイルまたはサポートされているテキストベースのファイルの最初の 15 MB の部分をクロールできます。HTML で参照されるリソース(CSS、JavaScript など)は個別に取得され、取得ごとに同じファイルサイズの制限が適用されます。ファイルの最初の 15 MB を超えると、Googlebot はクロールを停止し、最初の 15 MB のみをインデックス登録の対象として送信します。ファイルサイズの上限は、非圧縮データに適用されます。Google の他のクローラー(動画用 Googlebot、画像用 Googlebot など)では、制限が異なる場合があります。
少しわかりづらいが、結論としてはこういうことのようだ:
グーグルはさまざまなクローラーとフェッチャーを運用している:
- 全般的に、上限15MBを基本とする
ウェブ検索用のGooglebotでは、それに加えて独自の上限がある:
- テキスト系コンテンツでは2MBが上限
- PDFでは64MBが上限
- それ以外は一般的な15MBが上限(またはさらに大きい可能性もあり)
- SEOがんばってる人用(ふつうの人は気にしなくていい)
- 技術がわかる人に伝えましょう
グーグル検索SEO情報①
AEO/GEOは「SEOの拡張」――2026年に向けてマーケターが知るべき本質と新指標
リリー・レイ氏が2025年の激動を振り返る (Lily Ray on Substack) 海外情報
リリー・レイ氏が、2025年のAI検索の進化・変化を振り返り、記事にした。
かなりの長文だが、概要としては次のようなものだ:
2025年は、検索にとって転換点となる年だった。ChatGPTやGeminiのようなAIアシスタントの急速な台頭により、SEOの将来に対する不安が広がり、「GEO」や「AEO」をめぐる過度な期待が一気に高まった。多くの新しいツールや専門家が、「従来のSEOは時代遅れだ」と主張したが、提案する施策の多くは、次のどちらかだった:
- 既存のベストプラクティスを言い換えただけのもの
- リスクの高い手法
しかし、時が進むにつれて、より明確な全体像が見えてきた。グーグルは支配的地位を失うことはなく、むしろGemini、AI Overviews、AI Mode、Web Guideを通じて、AIを検索に直接統合していった。AIアシスタントがユーザーの情報との向き合い方を変えたのは事実だ。しかし、AIアシスタントがコンテンツを取得したり引用したりする際には依然として従来の検索エンジンを利用している。AIの回答における可視性は、次のものに引き続き依存している:
- クローリング
- インデックス
- 強固なSEOの基礎
重要な結論は、次のようにシンプルなものだ:
AEO/GEOは「SEOを拡張するもの」であり、「SEOを置き換えるもの」ではない。
AI主導の検索で成果を上げるには、強固なSEOの基盤、明確なブランドメッセージ、オフサイトでの信頼性、そしてクリック数よりも可視性、ブランドへの影響、需要に焦点を当てた新しい成功指標が求められる。
もう少し詳細に入った内容から、主要ポイントを簡潔にまとめると、次のようなものになる:
グーグル vs. AIプラットフォーム
ChatGPTは2025年初頭に急成長したが、法的・財務的・成長面での課題に直面した。
グーグルは初期のAIに関する失敗から立て直し、世界の検索シェアの90%以上を維持した。
AIプラットフォームが生み出すグローバルな参照トラフィックは、依然としてトラフィック全体の1%未満である。
グーグルはAI検索に置き換えられるのではなく、AIを自社の検索に取り込んでいる。
GEO/AEOをめぐる過熱
「SEOは終わった」という主張の多くは、新規参入者がツールを販売するためのものだった。
大半のGEOの手法は、名前を変えただけのSEOのベストプラクティスである。
一部で推奨された手法はリスクが高く、長期的な検索パフォーマンスを損なう可能性がある(つまり、AIでも不利になる可能性)。
既存のSEOプラットフォームは、企業からの信頼と規模の大きさにより、依然として優位に立っている。
AI検索の仕組み
AIモデルが行うのは「回答を統合する」こと。自ら検索しているわけではない。
クエリ・ファンアウトは、質問を複数のサブクエリに分解し、検索エンジンからデータを取得している。
そうした挙動のため、個々のAI生成クエリを追いかけても効果は薄い。明確なトピックにおける権威性に注力することの方が、はるかに重要である。
コンテンツとブランド戦略
AIシステムは、「テキスト」「動画」「画像」「音声」を処理する(マルチモーダルと呼ばれる)。
マルチモーダルなコンテンツは可視性を高めるが、新しい概念ではなく、AIがその重要性を高めているだけである。
ブランドは、自社サイト上で「誰であり、何を提供しているのか」を明確に説明する必要がある。
サイト外シグナルの重要性
AIは信頼性を評価するために、第三者による言及に大きく依存している。
「フォーラム」「レビュー」「ソーシャルプラットフォーム」「ニュースサイト」でのブランド言及が極めて重要である。
デジタルPRとSEOは、これまで以上に密接に連携する必要がある。
エージェント型コマース
AIが質問に答えるだけでなく、AIアシスタントがユーザーに代わって購入や取引を行えるようになりつつある。その背景には、グーグルのUCPやOpenAIのACPのような新しいプロトコルがある。
こうした機能はまだ初期段階だが、機械可読なコマースデータへの移行を示唆している。
成功指標の再定義
AIがより多くのクエリに直接回答することで、クリック率は今後も低下していく。
成功を判断する指標は、「検索トラフィック」ではなく、「ブランドの可視性」「需要」「コンバージョン」「検索シェア」などにしていくべきである。
AIにおける可視性指標は、正確な数値ではなく方向性を示すものである。
プラットフォーム全体で見ると、検索アクティビティの総量は減少しておらず、むしろ増加している。
非常に洞察に満ちた振り返りだ。AEO/GEOがSEOを置き換えるものではなく、その「拡張」であるという点に深く共感する。そして、サイト外のシグナルやデジタルPRがAI時代の信頼性構築において核心となるという指摘は、日本におけるマーケティング現場でも間違いなく重要になるだろう。
- すべてのWeb担当者 必見!
AIの台頭により「情報提供型コンテンツ」はもうSEOで通用しないのか?
条件を満たせば依然として通用する (Blue Array SEO) 海外情報
ChatGPTやGeminiのようなAIチャットや、グーグル検索のAI Overviewの登場により、情報提供型コンテンツはもはやトラフィック獲得に貢献しない。
このような意見もあるなかで、ここで紹介する記事は次のように述べている。
報提供型コンテンツは、量よりも「深さ」「実体験」「人間ならではの独自の洞察」を重視する限りにおいて、SEOの重要な要素であり続けている。
AI Overviewsや検索結果の高度化した機能により、シンプルな「ファネル上流(ToFU)」のクエリではクリックが大幅に減少したが、包括的で専門的なガイダンスへの需要が消えたわけではない。
AIで容易に再現できる、汎用的で代替可能なコンテンツは、もはやグーグルからもユーザーからも評価されない。成果を出すためには、AIのスニペットや簡単な検索結果では代替できない、具体的で、意見があり、実践的な価値を提供し、読者を次の行動へと導く情報提供型コンテンツが求められる。
納得のいく主張だ。元記事では、次のような点を論じている:
AIとSERP機能の影響 ―― AIOやLLMなどのツールは、「○○とは何か」「どれくらいかかるか」といった単純な質問に即答を提供するため、基本的なToFUクエリにおけるクリック数は大きく減少している。
「量産戦略」の終焉 ―― 「独自の視点を持たず、表層的な内容にとどまる薄いコンテンツ」を大量に生産する戦略は、ますます効果を失っている。
高品質コンテンツの定義 ―― 現在の情報提供型SEOで成功するには、次の要素を備えたコンテンツが必要である:
- マーケティング的な語り口ではなく、実体験に根ざしていること
- 明確な事例、注意点、オリジナルのメディアを用いた具体性
- ブランドの専門性を反映した、意見を持ち、自信のある視点
E-E-A-Tとの整合性 ―― グーグルは、経験・専門性・権威性・信頼性(E-E-A-T)を高いレベルで示すコンテンツを評価している。
ビジュアル検索・代替検索への移行 ―― ユーザーは、YouTubeやTikTokのようなビジュアルプラットフォームを利用する傾向が強まっている。その背景にある意図は、「説明を読む」だけでなく「実演を見る」こと。
事例 ―― 記事で紹介されている「切手収集」の低権威の趣味サイトは、商品や大規模な被リンクがなくても、初心者にとって本当に役立つコンテンツであれば、数千の実クリックを獲得できることを示している。
コンテンツ劣化への対抗 ―― 深さと実体験に重点を置くことは、記事が更新されず有用性を失うことで成果が低下する「コンテンツ劣化」への防御策となる。
参入障壁の上昇 ―― AIの台頭は情報提供型コンテンツを終わらせたのではなく、基準を引き上げただけである。「基礎的な情報」にはウェブサイトは不要になったが、深く人間主導の洞察を提供する存在としての重要性は依然として残っている。
ほかの場所でも手に入る情報を提供するコンテンツは、たしかに「終わった」といえるだろう。しかし、記事が指摘するように、AIが提供できず、そこでしか手に入らない情報を提供するコンテンツであれば生き残れる。
- すべてのWeb担当者 必見!
独立系SEOコンサルタントになるための5つのステップ
実力派SEOコンサルタントからのアドバイス (Brodie Clark on X) 海外情報
SEOコンサルタントとして独立を考えている人に役立ちそうな情報を紹介する。
「代理店やインハウス職を離れ、独立したSEOコンサルタントになるための5つのステップ」と題したブロディー・クラーク氏によるX投稿だ。
クラーク氏は、オーストラリア・メルボルンを拠点として活動するSEOコンサルタントだ。トリップアドバイザーやHPなどいくつものグローバル大企業のSEOにかかわった実績がある。
クラーク氏がアドバイスする独立のための5つのステップは次のとおりだ:
経験
独立に踏み切る前に、少なくとも4年(できればそれ以上)、誰かの下で実務経験を積んでいることを確認してください。これより早い段階では、「自営業として求められるレベルで、すべてを1人で管理する」には経験が浅すぎます。プロフィールを高める
誰かの下で働いている間に、業界内でのソートリーダーシップを通じて、自分自身のプロフィールを構築していくべきです。自分が語っていることを実践し、高品質な業界リサーチを自分のサイトで発信してください。リンクを獲得し、グーグルで上位表示されるような内容が理想です。一貫性を保ちましょう。フリーランス+フルタイム
フルタイムの仕事が許すのであれば、本業の外でも経験を積む必要があります。これは最も管理が難しい要素ですが、「営業力を高め」「ビジネスプロセスを構築し」「クライアントに成果を提供する」ためのことを、すべて1人で行えるよう強制的に鍛えられます。役職を離れる前に1年間はこれを続け、自分がその挑戦に耐えられるかを確認してください。これを「トライアル」と考えましょう。移行的アプローチ
可能であれば、エージェンシーやインハウス職を完全には辞めないでください。私はエージェンシーの視点からしか話せませんが、多くの場合、完全に辞められるよりも、何らかの形で関与を続けてほしいと考えるはずです。目標は、最大のクライアントのみを担当する業務委託として雇ってもらうよう説得することです。パートタイム雇用には移行しないでください。従業員ではなく、あなたのビジネスに直接支払われる形にしたいからです。リンクトイン上では自営業に見える状態にし、もう彼らのために働いていると表示しないことを交渉しましょう。これを4か月〜6か月間行います。専門特化+改善
私のコンサルティングのアプローチはやや非典型ですが(主に大規模なEC/オンラインショッピングモール/出版サイトと仕事をしています)、できるだけ早く特定のニッチに絞ることをおすすめします。独立系SEOコンサルタントにとって最も持続可能なのは、SaaSかECのいずれかです。ポジショニングを助け、信頼性を高めるために、ロゴや推薦文をできるだけ早くサイトに掲載しましょう。毎年、自分のロゴ/推薦文リストを振り返り、継続的な改善が見られる状態を目指すべきです。現在、SEO業界では高度なスキルを持つコンサルタントへの需要が非常に高まっています。ソートリーダーシップの一貫性と、サービスの信頼性を通じて、見込み顧客が安心して問い合わせできるようにしましょう。
コミュニケーション能力と営業スキルの向上にも常に取り組んでください。途中には困難な時期や仕事がまったくない時期もあることを覚悟しておきましょう。決して順風満帆ではありません。
5 steps to leaving your agency or in-house role and becoming an independent SEO consultant:
— Brodie Clark (@brodieseo) January 25, 2026
1. Experience
Ensure you have at least 4 years (longer ideally) of hands-on experience working under someone else before taking the leap. Any earlier than this is too fresh to be…
SEOコンサルタントとして独立を考えている人は参考にしてほしい。
- SEOコンサルタントとして独立したい人用(ふつうの人は気にしなくていい)
純度100%のAI生成コンテンツは2026年も短い命
うまく行く……ダメになるまでは (Glenn Gabe & Lily Ray on X ) 海外情報
人間の編集がほとんど関与しない、ほぼ100%のAI生成コンテンツは、検索でうまくいったとしても短命に終わり確実に検索結果から消え去る ―― そうした事例が2025年にいくつも見られた。AIの性能が進歩している2026年でもこの事実は変わりない。
米国の腕利きSEOコンサルタントであるグレン・ゲイブ氏のX投稿で、その状況がわかる:
これを「AI山」と名付けようと思う。AI生成コンテンツを大量に公開したサイトが急上昇し……そして最終的に崩壊した、また1つの例だ。
サイト運営者はきっと「AIコンテンツはすごい! トレンド入りしてるぞ!」と言っていたに違いない……クラッシュが起きるまでは。そして2025年12月のコアアップデートが展開されたとき、そのクラッシュはさらに深刻になった。
このサイトの問題はAIだけではないが、記事コンテンツはすべてAI生成(AIである確率100%と判定)だ。投稿全体に使われている画像もAI生成である……。
I think I'll coin this "Mt. AI". Yet another example of a site publishing a ton of AI-generated content that surged... and ultimately came crashing down. I'm sure the site owners were saying, "AI content is amazing! Look at our trending!" ... until the crash happened. And that… pic.twitter.com/DfWslqThrd
— Glenn Gabe (@glenngabe) January 21, 2026
同じく、米国の腕利きSEOコンサルタントのリリー・レイ氏も、X投稿で「うまくいった後にダメになった」例を紹介してくれている:
これは履歴書サイト内のサブフォルダで、「○○職種向けの履歴書例」という500ページ以上のプログラマティックなページで構成されている。
すべての<titles>はまったく同じ定型を使用。
ページテンプレートは非常によく似ている。
すべてのページでAggregateRating構造化データを誤用している
明らかなAIコンテンツが大量にある
うまくいっていた……ダメになるまでは。
This is a subfolder on a resume site with 500+ programmatic pages for "resume examples for ____ career"
— Lily Ray 😏 (@lilyraynyc) February 2, 2026
All <titles> use the exact same formula
Page templates are highly similar
All pages misuse AggregateRating Schema
Lots of obvious AI content
Worked until it didn't. pic.twitter.com/flBz4Wmm1f
2人が示したどちらのグラフも、検索トラフィック(検索結果での露出)が急激に増加し急激に減少している。
記事トピックのアイディア出しや記事の推敲を支援するならAIは活用価値がある。しかし、記事書きを丸投げする執筆代役としてのAI利用は現状ではおすすめできない。これが、AIコンテンツの量産ともなれば「大量生成されたコンテンツの不正使用」のスパムポリシーに引っかかる危険すらでてくる。
- すべてのWeb担当者 必見!
- この記事のキーワード
関連記事
うちのサイトは大丈夫? Googlebotは15MBまでしかインデックスしないって!【SEO情報まとめ】
2022年7月29日 7:00
【2026年版!?】ローカルSEOランキング要因【SEO情報まとめ】
2025年11月21日 7:00
Xは83%減、Facebookも60%減。こんなに変わったメディアのトラフィック源、では検索は……【SEO情報まとめ】
2025年8月22日 7:00
AI Overviewsは検索結果を「比較検討の場」に変える。84万セッションのデータで見えてきたユーザー行動の変化【SEOまとめ】
6月5日 7:05
昔のBaiduspiderよりひどい? 悪質AIクローラーが世界のサイトをゲリラ攻撃【SEO情報まとめ】
2025年4月4日 7:00
グーグル検索結果CTR調査【最新版】―― 1位CTRは19%~38%と業界格差が拡大【SEO情報まとめ】
2025年3月21日 7:00
バックナンバー
この記事の筆者

筆者の人気記事
「別タブで開く」リンク(target="_blank")は脆弱性あり?【SEO情報まとめ】
2020年3月13日 7:00
【重要】コアウェブバイタルとは? LCP/FID/CLSをわかりやすく解説【SEO情報まとめ】
2020年6月5日 7:00
新人に読ませておきたい「グーグルSEOでやったら本当にヤバいこと」【SEO記事12本まとめ】
2018年4月13日 7:00
グーグルが公式SEOチェックツールを公開【SEO記事11本まとめ】
2018年2月9日 7:00
もう待ったなし! グーグルが全サイトをMFIに強制移行へ(2020年9月予定)【SEO情報まとめ】
2020年3月27日 7:00
モバイルの「続きを読む」ボタンにグーグルの主要メンバーが不快感、将来は検索で不利になるのか?【SEO記事12本まとめ】
2017年2月10日 7:00




