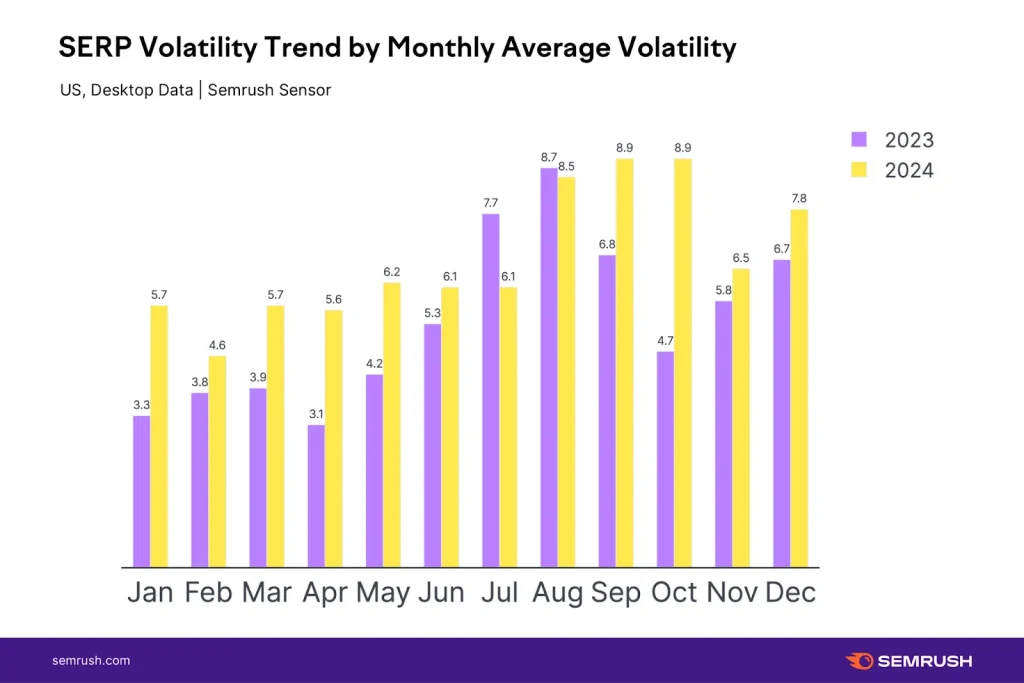
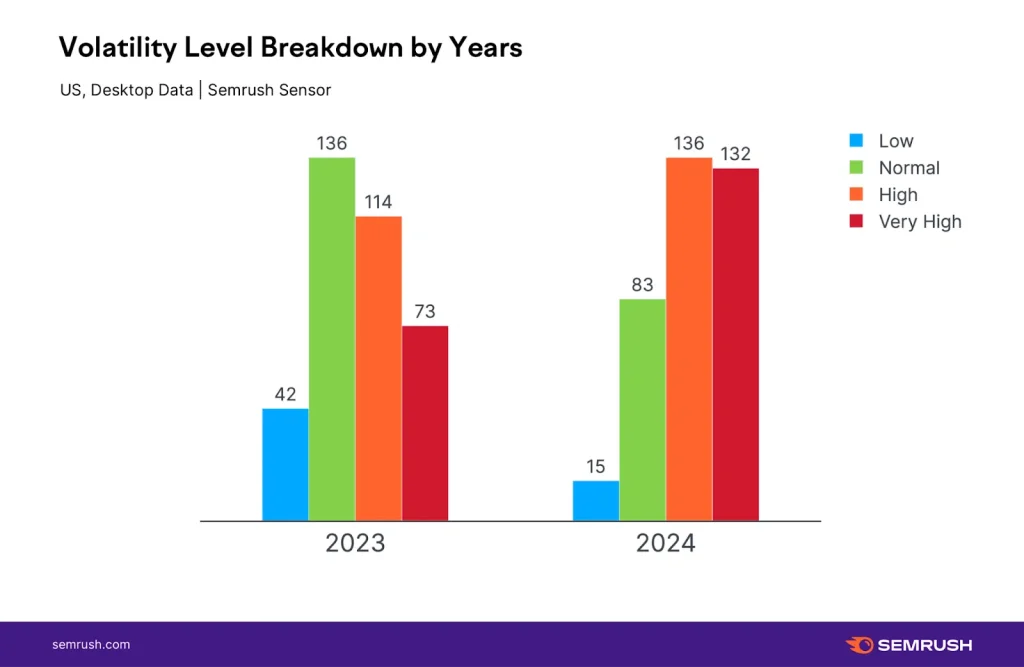
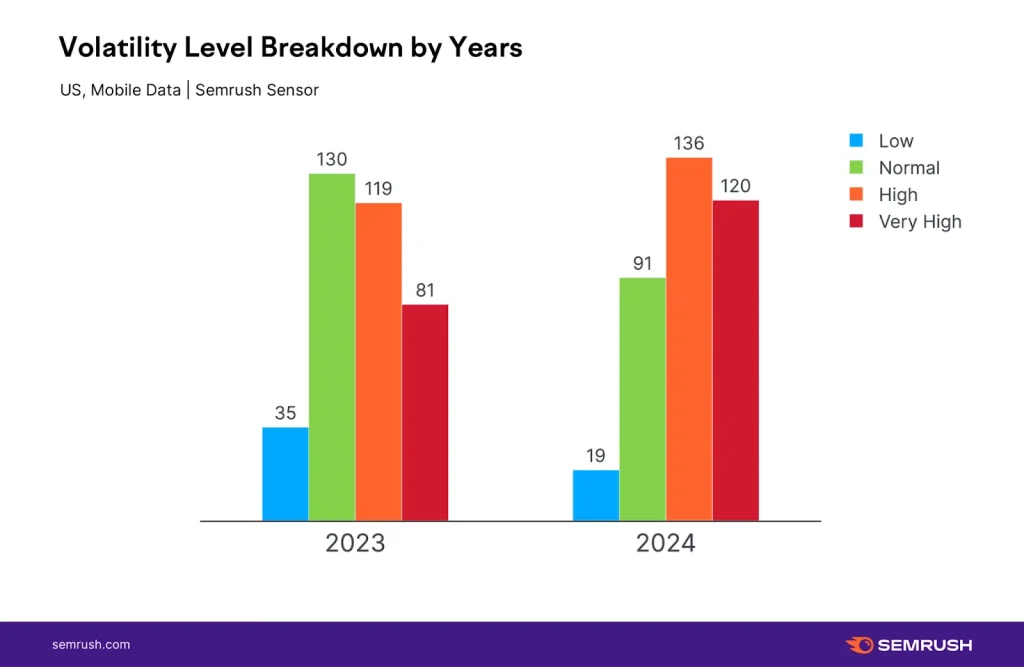
AI×SEO時代を生き抜くキャリア戦略セミナー開催レポート
AI技術の急速な発展により、SEO業界は歴史的な転換点を迎えています。
- 「従来のやり方が通用しなくなる」
- 「個人のスキルだけでは限界がある」
そんな不安を抱えている方も多いのではないでしょうか。
当社アイオイクスでは、創業20年以上の実績と業界での信頼を基盤に、この変革期をチャンスと捉え、新しい働き方とキャリア戦略を模索しています。
今回のセミナーでは、そうした取り組みの一端をご紹介するとともに、AI時代に理想的なキャリアを築ける環境について、実際の事例を交えてお話しします。
開催概要
開催日時: 2025年6月23日 18:00-19:30
テーマ: AI×SEO時代のキャリア戦略
登壇者: 遠藤 幸三郎(アイオイクス Webコンサルティング事業部長)× 豊藏 翔太 氏(シンクムーブ代表・アイオイクス Webコンサルティング事業部フェロー)
本記事のまとめ
- AI技術の台頭により、SEO業界が根本的な変革期を迎えている中で、SEO担当者が生き残り・成長するためのキャリア戦略とは?
- 従来の「作る主体」から「意味を設計する仕事」への転換が重要であり、ブランドや事業の深い理解が求められる時代に
- 独立か会社員かの二択ではなく、「自由と責任があるカルチャーでの会社員」という第三の選択肢にアイオイクスも候補に入れてほしい
- AI時代にチームで働く意味としては、組織で学習加速することと実験機会の数が重要
- 深い専門性(縦軸)とAIを活用した横断的スキル(横軸)を合わせたT型人材を目指すのが理想
遠藤氏パート:AI×SEO時代の新しいキャリア戦略
当社アイオイクスの遠藤氏は、SEO業界の変遷を3つの時代に分けて説明しました。
■SEO業界の歴史的変遷
- 2002-2010年: リンク主体のSEO時代
- 2010年代: コンテンツSEO時代(ペンギンアップデート以降)
- 現在: AI×SEO時代への移行
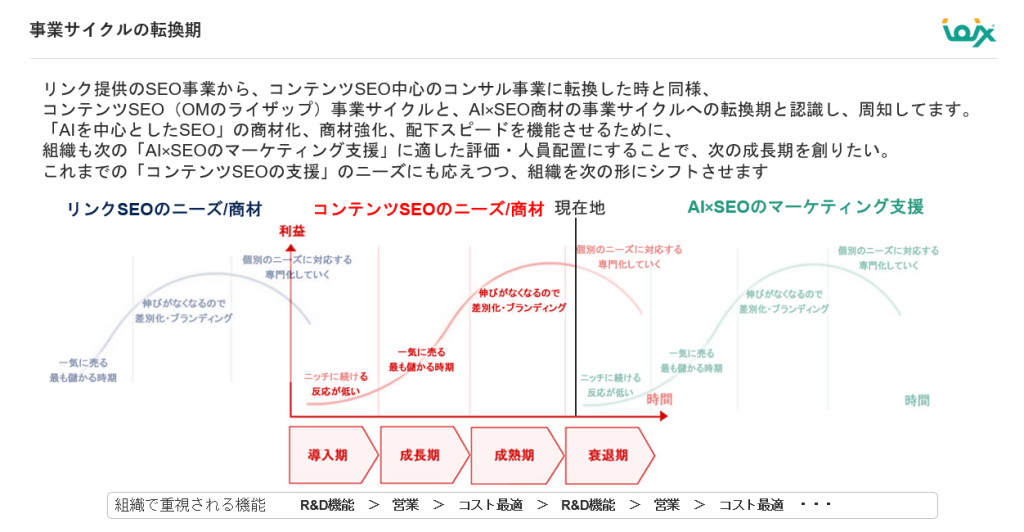
「今回のAIの流れは、過去のリンクSEOからコンテンツSEOへの転換と似たゲームチェンジの要素があります。だからこそ、事業のあり方や組織としての価値の置き方、人事評価制度、働くメンバーの強みも見直して再編成する必要があると考えました」
アイオイクスは、2002年とSEO黎明期から業界の大きな変化を20年以上見続けてきました。だからこそ、私たちは変化を恐れるのではなく、チャンスとして捉える文化が築かれています。
「何かを制作する」時代から「意味を設計する仕事」への転換を感じている。
遠藤氏は、SEOは従来の「何かを制作する時代」から「意味を設計する仕事」への転換が重要であると強調されました。
AI時代に求められる新しいSEO担当者の視点
- ブランドや事業の深い理解
- 生成AIに選ばれるサイト・ブランドの設計
- 多様化する検索行動への対応(動画、画像、音声など)
- 複数プラットフォーム(検索エンジン、SNS、動画プラットフォーム)を意識したコンテンツ設計
「これからのSEOの業務は、「ライティングだけ」では難しく、企業のブランドの文脈に沿って、どういった意味を訴求をしていくか。そして、それをどういうユーザーに対して、どのような接点で届けるかを設計する仕事が重宝されるようになると考えています」
実験重視の組織設計にシフト
AI時代の不確実性に対応するため、アイオイクスでは実験的な取り組みを重視していることが説明されました。
- 実験を行い、効果的な施策のみを展開
- 各社の施策効果を指標化し、有効性を検証
- 商材の形や提供価値を探求する継続的な改善
「AIにどういった形だったら好まれるか、それがどういうふうに取り上げられるのか、具体的に企業のビジネスでどんな数字に落ちるのかをファシリテートしていくことが求められています。SEOはかつてないくらい不透明な時代となりましたが、そんな中で新たなキャリアの選択肢として、SEO Japanを検討してもらえたら嬉しいです。」
豊藏氏パート:AI時代のキャリア戦略の実践例
豊藏氏は、AI時代のキャリア戦略について独自の視点を提示しました。
「AI時代のキャリア戦略を考える上で、独立するか会社員として働くか分かれると思います。個人的には、会社員として取り組むならアイオイクスのような自由と責任があるカルチャーで働くのも良い選択だと思います」
AI時代に会社員として働く場合の、自由と責任のバランス
豊藏氏自身の経験は、この「第三の選択肢」の実例となっています。
豊藏氏の過去の活動例
- 本業での挑戦: 営業からコンサル、事業推進、商材開発まで幅広い経験
- 副業での実験:アフィリエイト・転職サービス・レンタルスペース・広告運用など
「副業で得た経験、例えばInstagram広告を自身の副業で取り組んだ経験を、アイオイクスのセミナー集客に活用することもできました。逆に、アイオイクスで培った解像度の高いマーケティング視点を、自分のビジネスに応用することで成果を出せています」
AI時代に求められる「T型人材」はキャリアの選択肢が大きく広がる
豊藏氏は、AI時代における人材戦略について「T型人材」の重要性を強調しました。
「今はAIにより、自分の専門外の知識も取り込みやすくなった時代と考えています。だからこそ、自分の芯のある専門性と両立できると強い時代だと思ってます。縦の軸と横の軸両方を兼ね揃える事で、生成AIで5割、6割、7割ぐらいまで一定の品質が作れるようになりました。だからこそ、自分の専門分野を越境していくことでより広範なスキルが身に付きます。」
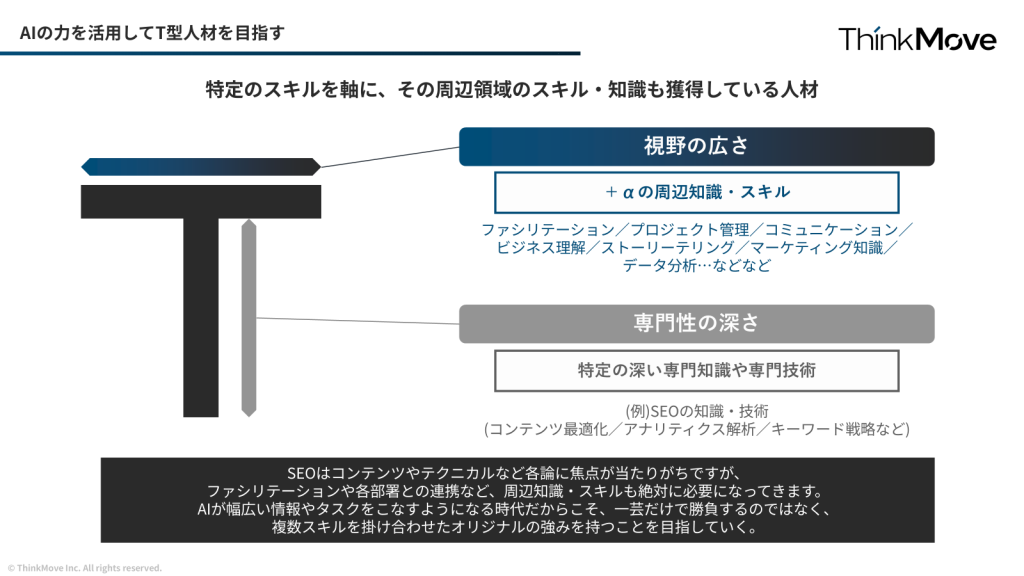
T型人材の構成要素
- 縦軸(専門性): SEOやマーケティングなど、深い専門知識
- 横軸(応用力): AIを活用して他領域の知識を効率的に習得
「マーケティングの根本は差別化の仕事です。だからこそ、生成AIで形にされたものから、81点、82点、83点と一点刻みで積み上げていくのが人間の役割と考えています。」
アイオイクスの仕事環境はAI時代に強みとなるか?
両登壇者のクロストークでは、AI時代におけるアイオイクスの強みについて詳しく言及されました。
- 20年以上の実績と信頼
- 創業: 2002年、SEO業界のパイオニア
- SEO Japan: 業界標準の情報発信プラットフォーム運営
- 大手企業実績: SMBC、パソナグループなど有名企業との取引
- 業界認知: 「SEO業界の歴史と権威がある」
「こうしたブランド資産は、AI時代に急に生まれるものではありません。SEO Japanの得てきた歴史は、中長期的なブランド資産として大きな強みになると考えています。」
AI時代のSEOコンサルティングは求められることが増える。個人対応の限界と組織の価値
遠藤氏は、AI時代のSEO案件について以下のように分析しました。
- (AI活用やAI対応の整理・検討など)やることが大幅に増加
- 従来のコンテンツ制作・テクニカルSEOも重要
- LLM最適化対応
- AI活用による業務効率化
- 多様化する検索プラットフォームへの対応
- 組織内AI導入支援
「SEOに取り組むには個人で対応すると、イチロー以上の守備範囲を求められます。(笑)すべてをカバーするのは現実的ではありません。だからこそ、AIの力を借りながら強い組織を作っていきたいと考えています。」
学習スピードが加速し、視座が向上するチームを作りたい。
AI時代のチーム戦略の優位性
- 学習スピードの加速: 優秀な人のAI活用方法を間近で学べる
- 視座が向上する: より高い視点でのAI活用方法を習得
- 実験機会がある: 組織リソースを活用した大規模な試行錯誤
「いきなりスーパーマンになるのは難しいですが、経験を吸収するには、チームの方が断然有利です。AIを使うことによって業務のスピードが速くなるからこそ、そのスピード感の中でチームに属して、スピード感の中でキャッチアップもよりスピードを持って進化できると考えます」
アイオイクスでの実践例
私たちのチームでは、ChatGPTなどのAIツールの利用を経費でサポートし、最新のAI活用ノウハウを全社で共有する文化があります。一人の発見が、チーム全体の成長につながる環境です。
アイオイクスのカルチャーと生成AIの考え方
アイオイクスのカルチャーには以下のような特徴があります。
- 実験推奨: 「これよりいいじゃん、やろう」という前向きな姿勢
- 失敗許容: 完璧性より実験精神を重視
- AIツール活用: ChatGPT等の経費利用可能
- 柔軟な意思決定: 現場の提案を積極的に採用
「セクショナリズムがある会社とは違って、『今はこの形で進めてるけど、こういう会社さんと連携したらもっといい価値を顧客に提供できるのでは?』といった試行錯誤ができる環境です」(豊藏氏)
また、遠藤氏はコンサルティングをする上で以下の観点を重視しているという話をしました。

- 現場: 実店舗視察、顧客体験の直接確認
- 現物: 実際のデータに基づく施策立案
- 現実: 机上の空論ではない実践的アプローチ
「実店舗がある企業の支援では、単純にウェブサイトを見るだけじゃなくて、実店舗に行って、どこのどういうシーンで、何をどうしゃべってるかとか、実体験を目にして、それを施策にどう落とすかを考えます」(遠藤氏)
採用情報:あなたも一緒に挑戦しませんか?
遠藤氏は求める人材像とカルチャーを以下のように話します。

ビジネスバリュー(お客様への価値提供)
- 正しいWeb集客を啓蒙する
- 理想と本音を傾聴する
- 事情をプロジェクトに落として伴走する
「知的好奇心、チーム思考、そして先々通じる汎用的なビジネススキルを重視しています。SEOをやるというよりかは、SEOをお客様のビジネスに活用するという視点が重要です。ビジネスバリューに共感いただけるパートナー(フリーランス、法人パートナー等)の方を募集しています。」(遠藤氏)
カルチャーバリュー(組織文化)
- 介在価値にこだわる
- 挑戦を続け成長する
- 3現から思考する
加えて、社内のカルチャーから生まれるバリューは上記3つの通り。ビジネスバリューのみならず、カルチャーバリューにも共感いただける方は、ぜひ一緒に働きましょう。
採用プロセスはカジュアルな対話重視
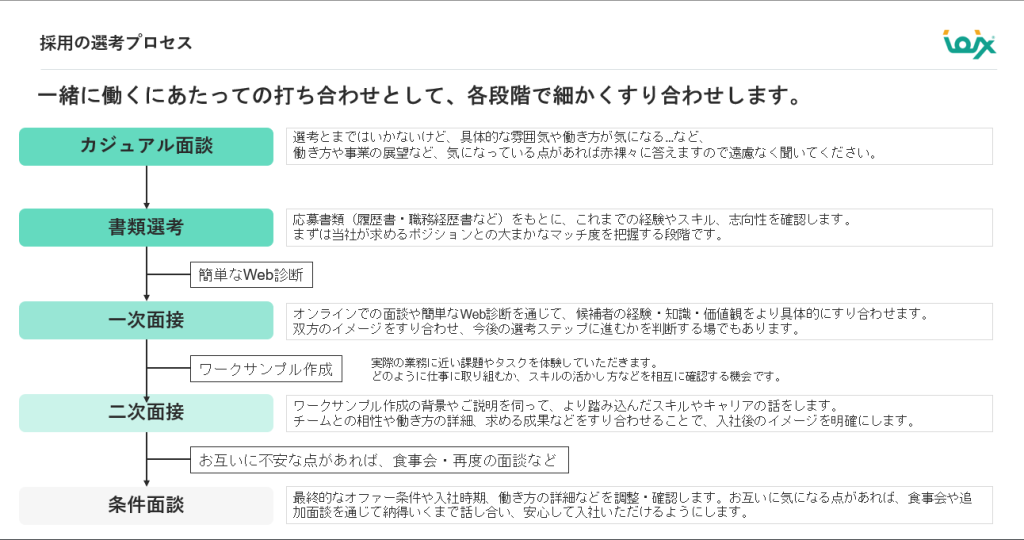
「面接官と受ける側という関係ではなく、ざっくばらんに話しながら、気が合えば一緒に働きましょうという感じです」(遠藤氏)
採用プロセスの特徴
- 複数回面談: 不安解消まで丁寧に対話
- 柔軟な形式: オンライン・オフライン両方対応
- インフォーマルな場: 食事会等での自然な対話
- 段階的参画: 業務委託からのスタートも可能
アイオイクスへの2つの参画方法
- 正社員採用: フルタイムでの本格参画
- 業務委託: プロジェクトベースでの協業
「気軽に話していただければと思います。わりかし面接するのが好きなんで、いろんな人がいて、すごい面白いんですよ」(遠藤氏)
まとめ:AI時代のキャリアに、アイオイクスという選択
AI時代のSEOは、単なる技術的スキルから「意味を設計する仕事」へと根本的に進化しています。
この大きな変革期において、一人で立ち向かうには限界があります。かといって、従来の硬直した組織では新しい挑戦は望めません。
そこで私たちが提案するのが、 「第三の選択肢」 です。
アイオイクスが提供する3つの価値
成長を加速する最適な環境
20年の業界実績による深い専門知識と、AI時代の変化に柔軟に対応する組織力。そして何より、失敗を恐れずに実験に挑戦できる前向きな文化があります。一人では不可能な大規模な試行錯誤と、チーム全体でのAI活用ノウハウの蓄積により、個人のスキルアップが圧倒的に加速します。
あなたらしいキャリアを実現
画一的な働き方ではなく、個人のライフスタイルに応じた柔軟な勤務形態を選択できます。副業との両立も積極的に支援し、多様な経験を通じてT型人材として成長していけます。自分のペースで、でも確実にキャリアを発展させる機会がここにあります。
変化し続ける業界での競争優位
専門性を深めながらAIを活用した横断的スキルを身につけることで、持続的な価値創出が可能になります。個人の成長が組織の発展につながる好循環の中で、変化を恐れるのではなく、変化をチャンスに変える力を培うことができます
独立でもない、従来の会社員でもない。自分らしく、でも一人ではできない大きな挑戦ができる。それがアイオイクスという選択です。
一緒に未来を創りませんか?
この変革期を一緒に乗り越え、新しいSEOの可能性を追求する仲間を探しています。
こんな方をお待ちしています
- AI時代の変化を恐れず、チャンスと捉えられる方
- 個人のスキルアップと組織への貢献を両立したい方
- 自由度の高い環境で、責任を持って仕事に取り組める方
- 実験的な取り組みや新しい挑戦に前向きな方
まずはお気軽にお話ししませんか?
興味をお持ちの方は、まずはカジュアル面談からお気軽にご連絡ください。