「SEOの意外な裏技」その10:robots.txtでリンクジュースの受け渡しをうっかりブロックしないために
自分のドメイン名にあるページにロボットをアクセスさせないための手段として、robots.txtを採用しているWebサイトが結構ある。確かにいいやり方だけど、僕らの元に寄せられる質問を見ていると、robots.txtを使ってグーグルやヤフー、MSNといった検索エンジンのロボットを排除するとは一体どういうことなのかってことに関して、少々誤解があるようだ。以下に、ロボットの排除方法をざっと分類してみよう。
robots.txt ―― URLへの訪問はさせないが、URL自体をインデックスに取り込んで検索結果ページ(SERP)に表示するのは許可する(よくわからない人は、下の例を見てほしい)。
メタタグ(meta要素)のnoindex ―― 訪問は許可するが、URLのインデックス化や、SERPへの表示はさせない。
nofollow属性の付いたリンク ―― 賢いやり方ではない。あるリンクにnofollowを付けても、他にnofollowの付いていないリンクがあれば、そのリンク先ページはインデックス化されてしまうからだ(ページのリンクジュースを「無駄」にしないためにこの方法を使うのならいいけど、その場合は、この方法でロボットを排除できるとか、SERPへの表示を防げるとは思わないことだ)。
以下は、robots.txtでロボットを排除しているのに、グーグルのインデックスには含まれているページの一例だ。
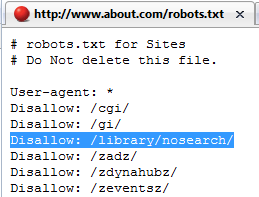

見ての通り、about.comは「/library/nosearch/」というフォルダにロボットがアクセスすることを明らかに禁じている。なのに、グーグルでこのフォルダのURLを検索すると、こんな結果が返ってくるんだ。
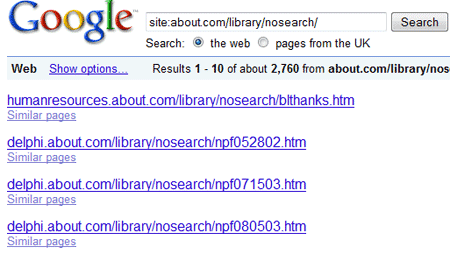
グーグルは、この「ロボット排除」を行っているディレクトリから2760件ものページを見つけ出している。これらのURLはクロールされていないわけだから、検索結果にはアドレスのみが表示される(グーグルはページの内容を見ることができないから、タイトルや説明などは付かない)。
ここで、もう一歩踏み込んで考えてみよう——検索エンジンの目に触れないようにしたページがあったとしても、それらのURLはリンクを獲得し、リンクジュースをはじめとするクエリ非依存型の順位決定要素を貯め込むことができる。でも、そこから外部へのリンクが検索エンジンの目に触れることはないんだから、これらのURLには貯め込んだものを「引き渡す」方法がないことになる。この状況を図で表すとこうだ。
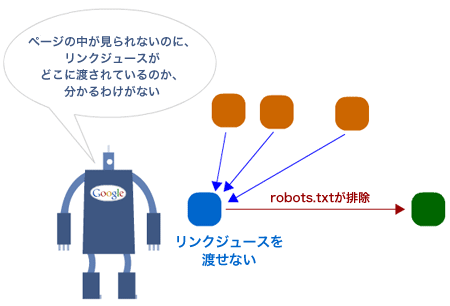
大事なのは次の2点だ。
robots.txtによってロボットを排除しているURLにリンクする場合は、nofollowを使ってリンクジュースを無駄に流さない。
ロボットを排除しているページが(特に外部リンクからの)リンクジュースを獲得していることがわかっている場合は、robots.txtではなくメタタグ(meta要素)を使って「noindex, follow」を指定し、自サイトの必要な場所にリンクジュースを渡す方法を検討する。
あるページをrobots.txtでdisallowするとクロールは禁止できるがインデックスは禁止されないため、リンクジュースの流れをコントロールしたければ、disallowしているページに対して、他の方法でインデックス自体を禁止するべきだという記事。
グーグルはrobots.txtでnoindexを指定することでインデックスを禁止できることを明らかにしているので、metaタグでnoindexを指定できない場合などは、この手法を使うのがいいだろう。
5月18日からのSMX Londonでみんなに会えるのを(それから、19日のウィルと僕のプレゼンも)楽しみにしているよ!
追伸:アンディー・ビアード氏が以前、このトピックについて「SEOのプロでも引っ掛かるリンク構築の落とし穴」という信頼できる記事を書いている。



この記事は、Daily SEOmoz Blog に掲載された以下の記事を日本語訳したものです。
原文:「Headsmacking Tip #13: Don't Accidentally Block Link Juice with Robots.txt」 by randfish (2009/05/17 18:25 PDT)
必見! Facebookいいね! 人気記事
最近(過去90日間)の記事で、Facebookの「いいね!」が多かった記事をお見逃し無く。
デジタルマーケティングの即戦力を2日間で育てます! 第24期「企業Web担当者 初級講座」6/13・6/14【2024年6月度】
 4,867 いいね!
4,867 いいね!「第6回 Googleアナリティクス4実践講座~GA4を使いこなす! 計測設定からレポート・分析活用まで」オンライン開催
1,164 いいね!Web担 編集後記 2024年3月
441 いいね!ライオンでアドビのCMSを導入! 導入の背景や活用方法を聞いた
432 いいね!【満員御礼】「GA4祭り」をテーマにアクセス解析の専門家が集結! 3月21日(木)@渋谷【Web担当者Forum Meet UP #2】
88 いいね!生成AI「Copilot」でMicrosoft 広告はどう変わる? ―Web担編集長・四谷が根掘り葉掘り聞いてきた!
85 いいね!STUDIO導入・内製化で運用コストが40分の1に! パシフィコ横浜のWebサイトフルリニューアルの成果
82 いいね!

ソーシャルもやってます!