

正規分布にならない例や理由 NPSの非正規分布は信頼できるデータ?
NPSの評価尺度データとしての信頼性を、正規分布という観点から考察したこの記事の筆者でありUXリサーチの専門家であるジェフ・サウロ氏が来日し、UXの定量化・指標化に関して講演を行います(詳しくは記事の末尾)。

評価尺度データに対する回答は多くの場合、正規分布の形にはなりません。
しかし、だからと言って統計計算が正確性に欠けるわけではありません。というのはその測定における誤差の分布は正規分布になるからです。
ベンチマークや比較テストがない場合、評価尺度データのトップボックス・スコアリング※を使うことで、データをまとめたり分割したりすることが容易にできます。
トップボックス・スコアリングが NPS のような評価尺度データとともに使われるもう1つの理由は、NPSデータが正規分布しないため統計計算が正確ではないのではないかという懸念を持つ人が多いためです。
各回答の度数のみを報告すれば、正規性についてのこういった懸念を避けることができます。残念ながら、11の回答を2つか3つにまとめてしまうと、精度やばらつきに関する重要な情報を落としてしまうことになるのです。
回答をいくつかのグループに分けると、レポートを簡潔にまとめられます(特に会社の上層部に報告するときは)。しかし、スコアが(以前の調査と比べて)統計的に良くなっているかどうか確信を得たい場合は、(標本サイズが小さくても高い精度を持つ)平均値と標準偏差を使います。そしてそれには、データの分布を考慮する必要があります。
「正規」とはどういう意味か
統計学を知り尽くしている方でも、データが正規分布になっているかは必ず確認したほうが良いと注意されることがあるでしょう。
嬉しいことに、評価尺度データ(たとえばNPSを計算するために使われる質問のようなもの)の分析における正規分布の役割は、統計学を1学期間受講しなければならないほど理解に苦しむものではありません。
正規分布(別名「ガウス分布」:私たちを混乱させるためにある名前としか思えませんが)とは、グラフにしたときに数値の大半が中央に集中し、左右対称の釣り鐘型に「分布」するデータのことを言います。
正規分布はあらゆるところで見受けられます。たとえば、身長、体重、IQスコアを示すグラフなどがそうです。次に示すグラフは、北米アメリカ人男性500人の身長の分布です。
典型的な釣り鐘型の分布が見られるでしょう。最も分布が多いのは平均身長5フィート10インチ(178cm)あたりで、それより高い人・低い人は左右同じように分布しています。

NPS データは正規分布に見えない
顧客ロイヤルティを示すのに人気の NPS は、「あなたがこの製品を友人に薦める可能性はどれくらいですか?」という質問に対して、0~10の11ポイントの評価尺度で答えるものです。
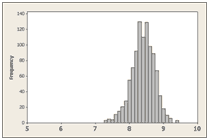
次に示すのは、あるコンシューマ向けソフトウェア製品を友人に「薦める可能性」についての673の回答をグラフにしたものです。回答の平均は8.4ポイントで、標準偏差は1.8です。

グラフはまったく釣り鐘型には見えませんし、左右対象でもありません。研究者が信頼区間や、t検定、あるいは平均と標準偏差といった、一般的な統計テクニックを使うことに懸念を抱くのはもっともなことです。彼らはこのような非正常データを目にすると逃げ出したくなるのです!
正規性はなぜ重要か
正規性が大切な理由は2つあります:
- 統計的な検定は、測定エラー(誤差)が正規分布していることを前提にしている。
- データが正規分布でないならば、平均値より上と下のパーセンテージについて正確に語ることができない。
測定における誤差
測定誤差(エラー)と言っても、だれかが質問の意味を取り違えたとか、調査から得たデータを読み違えた、といった類のエラーではありません。どの標本からでも生じ得る、システマティックでないもののことを指します。
標本から平均を算出する際、未知の母平均が推定されます。そしてその推定値は、ほぼいつも上か下かに少しずれています。
標本平均と母平均の差のことを標本誤差(サンプリングエラー)と言います。そしてそれは独自の分布をなします。この分布は正規なものであってほしいのです。標本データが正規分布であるならば、標本平均の分布もまた正規であるはずです。
残念ながら、ほとんどすべての評価尺度データは正規分布ではありません。ですから、標本平均の分布を調べる必要があるのです。けれども、標本平均が1つしかなければ、標本平均の分布がどのような形になるかをどうやって知ることができるでしょうか?
もし、持ち時間がたっぷりあるなら、無作為に選んだ30人の人に、友人にその製品を薦めるかどうかを尋ねることができるでしょう。そしてその平均を見つけ出してグラフにし、また最初からやり直し、この作業を何度も何度も繰り返すのです。
あるいは、大きな標本データから小さな無作為の標本をいくつも採って、いくつかのコードを使い、その実験をシミュレーションするのもいいでしょう。
私は後者を選びました。
標本平均の分布
私は大きな標本(673の回答)を使って、無作為に選んだ小さな標本の平均を計算する簡単なプログラムを作りました。私は標本サイズ30と10と5についてそれぞれ1000回繰り返しました。各々の標本平均の分布グラフは次に示したとおりです。


標本サイズが30と10のときの1000回平均は釣り鐘型で左右対称になっていますから、正規分布です。標本サイズが10のときの分布がすこし横に広くなっているのは、標本サイズが小さいほど変動性が大きくなるためです。
一方、標本サイズが5のときは分布の左右対称バランスが崩れ、歪んでいます(スコアの低い方に値が偏っている)。標本誤差が正規分布からずれているという証拠です。
注記:正規性検定の種類によってはp値が発生することがあります。こういったものは正常値から少しずれるだけでも過剰に反応してしまう傾向があるため、薦められません。通常の確率プロット(Q-Qプロット)のデータを見るのが最も信頼性の高い方法です。ここで柱状のグラフを用いたのは、釣り鐘型の形がわかりやすいからです。
中心極限定理
ここまで見てきたものは「中心極限定理」と呼ばれるもので、統計学においては最も重要な概念です。中心極限定理によると、母集団データがどれほど不格好な非正規型であっても、(特にその標本サイズが30より大きい場合)標本平均値の分布は正規型になるのです。
私の行った再サンプル実験からわかるように、中心極限定理が働き始めるのは標本サイズが30よりずっと小さいときです(10の標本はほぼ正規の形です)。データがどのサイズでどの程度正規に見えるかは、データによるのです。
ありがたいことに、標本分布が正規かどうかを知るためにはソフトウェアプログラムをコーディングしなければならない、ということはありません(統計を使わない別の言い訳が必要になりますね)。
標本サイズが小さくて(10未満)正規分布にならなくても、信頼区間や、t検定、ANOVA(分散分析)などの統計テストで十分な結果が得られます。誤差が生じる場合でもわずか1%から2%くらいなので、許容範囲に収まります(GEP Box (1953) Non-normality and test on variance. Biometarika, 40 参照)。
言い換えれば、95%の信頼区間を計算しているつもりでも、実際には94%の信頼区間の計算になっているかもしれないということです。
まとめると、大きい標本サイズ(30以上)の評価尺度については、正規性は気にしなくていいのです。小さいサイズ(特に10以下)に関しては、ほとんどの統計テストでささやかな(でも許容できる範囲の)誤差が生じるでしょう。
母集団分布
標本データの形が統計テストの正確さを左右することはおそらくありません。しかし、「母集団スコアの何パーセントが平均またはある点より上・下にある」といった表現に影響を及ぼします。
たとえば、「全ユーザーの半数が、製品を薦めるかどうかのアンケートで平均8.4ポイントを上回るスコアをつけることを95%確信しています
」といった表現です。
このような表現に至らせる平均値とは、データが左右対称で、だいたい正規分布をなすことを前提としています。しかし、先ほどのグラフからわかるように、そうはなりません。これは作業所要時間データでも起こる問題で、正規分布をなさないケースです。
評価尺度のデータについては、解決は容易です。あるポイントを上回るスコアを付けたユーザーの割合に関するステートメントを用意したいなら、個別の回答をカウントすればいいのです。たとえば、「ユーザー673人のうち362人(54%)が9あるいは10ポイントと回答しました(「推奨者」と分類します)。二項信頼区間で計算すると、全ユーザーの50%から58%は推奨者であると95%確信することができます
」といったように。
もう1つの選択肢は、正規分布に沿うようにスコアを変換することです。これは作業所要時間データを使用するときにも用いる修正プロセスです。変換されたデータが正規分布になれば、パーセンテージに関するステートメントも正確になります。
正規性のまとめ
要するに、大きい標本(30以上)であれば、正規性は気にしなくてもかまいません。それよりも小さい標本の場合は、誤差の分布が正規あるいは正規に近いものになります。データが正規のものから外れていても、ほとんどの統計テストで信頼できる正確な結果を得ることができます。
正規性が重要になるのは、ある値より上ないし下の母集団の割合についてステートメントを用意しなければならない場合です。そのようなときは、回答度数を使うかデータ変換を行うといいでしょう。
ここでは「製品を他人に薦める可能性」の回答だけを例として挙げてきましたが、他のすべての評価尺度データ(たとえ ば、システムユーザビリティ・スケール(SUS)や、シングル・イーズ・クエスチョン(SEQ))にも同じ考え方を適用できます。
私のアドバイスとしては、データが正規分布になるかどうかを心配するよりも、そのデータの「代表性」を気にするべきだと思います。つまり、あなたの標本はこれから推論する母集団を代表するものなのか、よく吟味しなければならないのです。
非正常なデータで誤差が生じることよりも、間違った人々(母集団)について「正しい結論」を導くほうが、よほど大きな問題です。代表的でない標本の説明を可能にする統計操作など決してありません。
正規分布や統計におけるその重要性をさらに学びたい方はCrash Course in zScoresを参照してください。
UXを指標(メトリクス)の観点で考えるセミナーイベント
本記事の筆者でありUXリサーチの専門家であるジェフ・サウロ氏も来日して講演するセミナーイベント「ソシオメディア UX戦略フォーラム 2015 Fall」が、2015年10月7日~8日に、東京都千代田区のステーションコンファレンス万世橋で開催されます。
本記事を翻訳したソシオメディア株式会社が開催している「UX戦略フォーラム」シリーズの2015年第3弾で、今回のテーマは「メトリクスの探求」。
ジェフ・サウロ氏は、1日目のキーノートと2日目のセッションに加え、パネルディスカッションでも登壇します。
サウロ氏をはじめとする、「UX」「顧客ロイヤルティ」「NPS」とその指標化に関する国内外の専門家が集い、UXデザインの計測や分析、そしてそれらの数値をどうマネジメントに活用するかといったことを探るイベントです。
- イベント名称: ソシオメディア UX戦略フォーラム 2015 Fall
- 開催日時: 2015年10月7日(水)~8日(木)
- 開催場所: ステーションコンファレンス万世橋(東京都千代田区)
- 主催: ソシオメディア株式会社
- 詳細情報と参加申し込み:
https://www.sociomedia.co.jp/6073



ジェフ・サウロ(MeasuringU)

ジェフ・サウロ(Jeff Sauro)
ジェフ・サウロはシックス・シグマに精通した統計アナリストであり、ユーザー・エクスペリエンスの定量化における第一人者である。彼は統計的なデータを理解させ、そしてアクション実行へと導く専門家。そしてアメリカコロラド州デンバーにある、UXリサーチ会社 MeasuringU(MeasuringU.com)の設立者である。 MeasuringU の設立以前は、Oracle、PeopleSoft、Intuit、そして General Electric で働いてきた。
ジェフはこれまで20以上の専門家のレビューを受けたリサーチ記事、そして5冊の統計とユーザー・エクスペリエンスに関わる書籍を発表している。スタンフォード大学にてラーニングとデザイン・テクノロジーの修士を取得。またデンバー大学にてリサーチメソッドと統計学の博士を取得している。
この記事は、Measuring Usability に掲載された以下の記事を日本語訳したものです。
原文:「Should The Net Promoter Score Go? 5 Common Criticisms Examined」 by Jeff Sauro(2014/07/22)
翻訳:ソシオメディア株式会社
必見! Facebookいいね! 人気記事
最近(過去90日間)の記事で、Facebookの「いいね!」が多かった記事をお見逃し無く。
デジタルマーケティングの即戦力を2日間で育てます! 第24期「企業Web担当者 初級講座」6/13・6/14【2024年6月度】
 4,867 いいね!
4,867 いいね!「第6回 Googleアナリティクス4実践講座~GA4を使いこなす! 計測設定からレポート・分析活用まで」オンライン開催
1,164 いいね!Web担 編集後記 2024年3月
441 いいね!ライオンでアドビのCMSを導入! 導入の背景や活用方法を聞いた
432 いいね!話題の「ChatGPT」こんなに使えたら本当にすごい! 目からウロコの使い方を解説|GPTs活用事例も
289 いいね!【広告主・マーケター限定】デジタルマーケターズサミット 2024 Winter 2/28、29オンラインLIVE配信
258 いいね!【満員御礼】「GA4祭り」をテーマにアクセス解析の専門家が集結! 3月21日(木)@渋谷【Web担当者Forum Meet UP #2】
88 いいね!生成AI「Copilot」でMicrosoft 広告はどう変わる? ―Web担編集長・四谷が根掘り葉掘り聞いてきた!
85 いいね!

ソーシャルもやってます!