アルゴリズム検索の結果を相手に仕事をしている検索マーケティング担当者の大多数は、自分たちが少なくとも検索エンジンの「最新アルゴリズムを把握している」と主張しているし、僕がこれまでに聞いた(あるいは、そういう意味で言えば、担当した)クライアント仕事では、9割方この話が少なくとも1回は話題に上っていた。
しかし、この点については、まだ多くの点で本当のことがわかっておらず、最近SEOに手を染めたばかりの人たちにとっては、おそらく最も気の重い側面だろうと思う。
というわけで、みんなの苦労を少しでも軽くするため、しょっちゅう変わり続ける検索エンジンの検索結果算定式に、どうすれば遅れを取らずにいられるかという問題に関して、みんなが持つ共通の疑問に答えておいたほうがいいんじゃないかと思ったんだ。
アルゴリズムとは何か?
グーグル、ヤフー、マイクロソフトは、それぞれどのようにして、検索アルゴリズムを検索結果に反映しているのか?
「アルゴリズム」とは、非常に複雑な方程式(または方程式の集合)のことだと思っておけばいいだろう。そして検索エンジンは、アルゴリズムを使って検索結果の並べ替えを行う。以下に、非常にシンプルな検索エンジンアルゴリズムの例を示しておいた。
上記の例だと、検索エンジンは3つの単純な要素に基づいてページにランクを付けている。そのページの「検索語が現れる回数」「被リンク数」「信頼できる被リンク数」だ。実際には、グーグルの場合は200種以上の要素(順位決定要素)を含むアルゴリズムでランクを決定しているそうだ。検索エンジンアルゴリズムにおける順位決定要素は、大きく分けて2種類(派生的な分類も数えれば何十種も)に分けられる。1つがクエリ依存型要素で、もう1つがクエリ非依存型要素だ。
クエリ依存型要素――ユーザーが検索キーワードを送信したときに実行する順位決定メカニズムの一部だ。検索エンジンは、ユーザーが何を探そうとしているのかを知らない。したがって、あらかじめ計算しておくことができない多数の変動要素があり、検索のたびに計算しなければならない。その中には、ユーザーが入力した検索語を含むページの特定や、キーワードに基づく関連性の算出、そして、より的確な結果を返すためのユーザーに関する地理的情報や個人化情報の収集などがある。リソースを節約するため、検索エンジンは非常に検索頻度の高い結果について、膨大な量のキャッシュを定期的に作成しており、必要以上の計算を行わずに済むようにしている。
クエリ非依存型要素――検索エンジンがクエリ実行の前からそのサイトあるいはページについて持っている情報だ。最も代表的な例は、そのサイトまたはページに集まっているリンクを元に、ウェブコンテンツの世界的人気度を測定するグーグルのPageRank(ページランク)だろう。PageRankのほかには、TrustRank(信用度に基づくリンク測定指標)、ドメイン名関連性(該当コンテンツを掲載しているウェブサイト)、キーワード頻度(または検索語の重み)、そしてページの鮮度なども、こちらのグループだ。
アルゴリズムは、検索エンジンの順位並べ替えメカニズムとして機能するため、検索結果に直接影響を及ぼす。以下の画面で、SEOmozのブログ記事がグーグルの「Google Technology」ページの下位で、AMS.orgの「How Google Finds Your Needle in the Web's Haystack」ページの上位に表示されているのは、グーグルのアルゴリズムがこの順番に並べ替えたからだ。
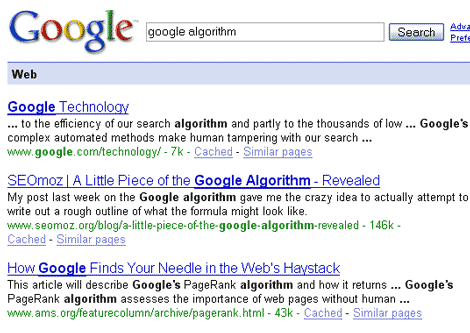

一昨年僕は、グーグルのアルゴリズムを構成していると思われるマクロ要因について、おおよその推測を示した記事を書いたけど、これを読めば、細かく考えずにアルゴリズムを捉える助けになるかもしれない(英文)。
なぜSEO担当者は、検索アルゴリズムに注意を払わなければならないのか?
どうしてって、それはもちろん、検索エンジンがそれを使って検索順位を決めてるからに決まってる!
いや、でもまじめな話、プロのSEOならば、より多くの検索トラフィックを獲得しようと志すこと、そして検索エンジンアルゴリズムについてより深く理解すること、さらにはそれらに影響を及ぼす要素を徹底的に研究することが、仕事の質を上げるのに必要不可欠だと言っていい。
タイムマシンで、2002年の僕を今の2008年に連れてきてみれば、SEOとして悲劇的な過ちをたくさん犯すことで、当時キャンペーンで獲得できていたはずの価値が、おそらくは減じられていたのだろうと悲嘆に暮れてしまうと思う。検索結果に影響を与える手法を初めて学んで以来6年が経ったが、その間アルゴリズムも大きく変わった。そこで、この6年にアルゴリズムが進化してきた過程をざっと見てみよう。
- リンク価値測定基準における固有信用度の導入
2002年、検索エンジンの順位決定の世界では、まだPageRank(そう、ツールバーとかにある小さな緑色のアレ)が大きな支配力を持っていた。アンカーテキストと高い値のPageRankを集めれば、事実上どんなものでも高い順位を獲得できた。ところがここに、「信用度」の概念が組み込まれるようになり、生のリンクジュースの重要性は低下し、「信頼できる」リンクソースの重要度が上がった。現在では後者の方が、リンク評価の上で重要な要素となっている。 - 各ページの重要性よりドメイン名の信用度を重視
どの検索エンジンも、ドメイン名の「強さ」について重み付け評価を行うある種の数式を開発してきた。その結果、あるドメイン名にあるコンテンツはすべて、そのドメイン名の強みという恩恵を受ける仕組みになった。これは、2002年の時点でまだほとんど見られなかった現象で、当時各ページは、掲載ドメイン名とほとんど関係なく、強さは一律に見なされていた。 - リンク増加の経時分析
グーグルがこの特許技術「Information Retrieval Based on Historical Data」(国内特許名「ドキュメントをスコア付けする方法」)を使い、スパムや不正操作の可能性を突き止めるため、リンク評価に時系列的増減のデータを盛り込んでいることに、世界中のSEOが初めて気づいたのは2005年のことだ。悪名高き2003年11月の「フロリダ」アップデートには、この特許で言及している属性要素がいくつか見受けられた。このアップデートでは、数多くのアフィリエイトサイトと初期のSEO化サイトが、大きく順位を落とした。 - アンカーテキストのパターン評価によるスパム検知
信じられないかもしれないが、まったく同じアンカーテキストのリンクを5万件集めることで、良い順位が獲得できてしかもお咎めなし、という時代があった。現在検索エンジンは、不自然に目立つリンク傾向を持つサイトに対して、非常に懐疑的な見方を示す傾向が強い。 - 新規ウェブサイトのサンドボックス化
サンドボックス適用の例が初めて目立つようになったのは、2004年3月だったと思う。それ以来、新規ウェブサイト開設の様子が変わってしまった。グーグルは、商業的なキーワードをターゲットにした新しいドメイン名で、なおかつ強く信頼できるリンク傾向を迅速に獲得できていないサイトに対して取り締まりを強化し、インデックスから大量のスパムを除去した(そして、新しいサイトやブランドをSEOで支援することが、頭の痛い仕事になった)。 - ブログにおけるコメントスパム問題の修正
僕が2003年に、ある特定のEコマース関連のキーワードで検索順位を上げたいというクライアントを担当していたとき、英国の友人に話したことなのだけど、これから3週間で8000件程度のリンクを獲得して、翌月には1位になってみせると言ったことがある。当時は、ブログのリンクが驚くほど力を発揮していたブログコメント全盛の時代で、コメントスパマーはたいてい、「1万人ものブロガーなんだぜ。正しいことに決まってるだろ!」と言ったものだ。しかしこれは、あまりにうますぎる話だということで、nofollow属性付きのリンクや、インテリジェントなアルゴリズムが登場して、評価すべきコメント上のリンクを選ぶ方法が確立されたため、この戦術はほとんど使えなくなってしまった。 - 相互リンク戦術に対する取り締り
わずか半年ほど前でさえ、不動産業界では非常に多くのサイトが比較的単純な相互リンク手法を多用していた。しかし今は違う。もはやそれらのサイトの多くが以前のような順位を獲得することはできず、不動産業界のSEOは2007年に比べて、その様相が大きく変わった。
これらは、この6年でアルゴリズムに加えられた修正のほんの一部だ。そして、十分に注意を払って、いつも変化のちょっと先を進むことによってのみ、クライアントと自分自身のプロジェクトに対し、可能な限り最高の戦略的指針と助言をもたらすことを望めるんだ。
アルゴリズムの変化、とりわけ新しいテクニックの台頭と古いテクニックの衰退に遅れないようについて行くことは、優れたSEOにとって必要な条件というだけでなく、検索エンジン市場で仕事をする者の責任なんだ。
どうすれば、アルゴリズムの進化における最新の傾向を調べ、ついていくことができるのか?
それにはいくつか、ごく簡単で、ほぼ誰にでも実行できるすばらしい方法があり、これを使えば主な検索エンジンのアルゴリズムについていけるようになる。それらをこれから紹介しよう。
複数のウェブサイトを管理(あるいは少なくとも、キャンペーンおよび検索ビジターのデータを収集)していれば、根拠のある決断をするうえで、最高の情報を得られる。また、検索エンジンの順位決定傾向や、マーケティングおよびコンテンツの種類別に見て異なるサイトのトラフィック獲得傾向を観察することで、検索エンジンの動向について、直観を働かせて推理できる。それからさらに、テストして調整し、再評価を行えば、求める知識が得られるだろう。
下記の優れた情報ソースを日常的に読めば、アルゴリズムについて洞察を深めるうえで非常に役に立つ。
- SEO by the SEA――ビル・スロウスキ氏のブログは、検索エンジンが次に向かおうとしている先の手がかりとして、特許出願やIR(情報探索)関連の研究論文などを定期的に取り上げている。
- SEO Book――アーロン・ウォール氏以上に、検索エンジンのターゲット化に関する有効な戦術で、すばらしい洞察を与えてくれる人物はいない。
- TheGoogleCache――Viranteは定期的に質の高い検索エンジンのテストを実施し、そのデータをここで公開している。
意味を成さないキーワードやドメイン名を使ってテストを実施すれば(さらに外部リンクの補正も行えば)、検索エンジンがどの要素を重視しているのか、すばらしい対比テストの結果を得ることができる。実際のテスト手順については、改訂版初心者ガイドに詳しく書いたから、参考にしてほしい。
調査から得た知識を、どのように実際のキャンペーンに活かせば良いのか?
基本的にはセオリーと呼ばれている知識を使うときと同じ、すなわちテストと反映の繰り返しだ。たとえば、コンテンツ内でリンクしたほうが、サイドバーからリンクしたり、トップレベルのメニューにあるナビゲーションからリンクするよりも高いSEO価値が得られるという強力な証拠を見つけたり、信頼できるソースからそういう話を聞いたりした場合、サイトの1セクションを使い、Wikipediaのようにコンテンツページ内ですべて内部リンクさせるようにしてテストを行う。そして、1か月後に調べてみて、検索エンジンが(あるいは特定の検索エンジンが)それらのページすべてをクロールして、その検索エンジン由来のトラフィックが通常よりも増えていれば、その効果が「ありそうだ」と判断し、同じことを別のセクションでテストしてみるといい。
別の手として、意味のない単語に関して、上記のテストを行ってみるのも良い。この方法だと、現実的なフィードバックがあまりない代わりに、サイトには何の危険も及ばない(^-^)
全般的に言えることなんだけど、アルゴリズムの変化についていくことは、節税や職場への近道や、もっと上手いタマネギの刻み方などといった、あらゆる最適化戦略と通じるところがある。読んで、調べて、テストする。そして、良好な結果が得られたら、実施してみる。
アルゴリズムの調査および評価方法については、まだ他にもたくさんあるけれど、それは別の機会にとっておくとしよう。それまでに、アルゴリズム研究に対するみんなの考えや、うまくいった体験などについても聞いてみたいな。

")



この記事は、Daily SEOmoz Blog に掲載された以下の記事を日本語訳したものです。
原文:「How to Track the Evolution of Search Engine Algorithms & Why It's Important to Do So」 by randfish (2008/02/20 01:21 PST)
必見! Facebookいいね! 人気記事
最近(過去90日間)の記事で、Facebookの「いいね!」が多かった記事をお見逃し無く。
デジタルマーケティングの即戦力を2日間で育てます! 第24期「企業Web担当者 初級講座」6/13・6/14【2024年6月度】
 4,867 いいね!
4,867 いいね!「第6回 Googleアナリティクス4実践講座~GA4を使いこなす! 計測設定からレポート・分析活用まで」オンライン開催
1,164 いいね!Web担 編集後記 2024年3月
441 いいね!ライオンでアドビのCMSを導入! 導入の背景や活用方法を聞いた
432 いいね!話題の「ChatGPT」こんなに使えたら本当にすごい! 目からウロコの使い方を解説|GPTs活用事例も
289 いいね!【広告主・マーケター限定】デジタルマーケターズサミット 2024 Winter 2/28、29オンラインLIVE配信
258 いいね!【満員御礼】「GA4祭り」をテーマにアクセス解析の専門家が集結! 3月21日(木)@渋谷【Web担当者Forum Meet UP #2】
88 いいね!生成AI「Copilot」でMicrosoft 広告はどう変わる? ―Web担編集長・四谷が根掘り葉掘り聞いてきた!
85 いいね!

ソーシャルもやってます!